
Five Things (May 23, 2026): AI in life sciences
Jassi Pannu on AI and biosecurity, RAND/Helena AIxBio biosecurity mitigations, Blekhman on genomics AI, Nature’s AI scientists week, AI in peer review.
Big week in AI in life sciences (AIxBio). The Nature drop this week included three papers on AI scientists alongside an editorial and a comment piece pushing back on the whole project. Add Jassi Pannu’s three-part series on AI for biology, a new RAND/Helena workshop report on AIxBio mitigations, Ran Blekhman’s take on AI in genomics, and a new study on AI in peer review and I’m landing on a theme this week: how fast should we let AI into the production of biological knowledge, and what gets lost if we don’t slow down to ask?
Jassi Pannu’s case for shaping AI-for-biology before it shapes us
RAND and Helena on AIxBio mitigations
Ran Blekhman on the state of AI in genomics
Nature’s AI scientists week, and the editorial pushback
45 expert scientists review the reviewers
1. Pannu’s three-part case for shaping AI-for-biology
Jassi Pannu (Johns Hopkins, Center for Health Security) published a three-part series last week on shaping AI progress for biology and biosecurity.
Part 1 sets up the series. AI will compress decades of biological research into years, but cures won’t arrive by default, and the same systems that enable them can lower the barrier to weaponizing pathogens. We need proactive policy on both sides.

Part 2 is where it gets interesting. Pannu lays out what she calls autonomous biological discovery: AI systems that automate every step of the research cycle, including managing the cycle itself, with orgs like Isomorphic Labs, FutureHouse, Ginkgo Bioworks and others entering the fray.
AI-enabled feedback loops will be able to extend beyond this, exploring parts of biological space that nature has not.
Evolution selects for reproductive success and gets stuck in fitness valleys. AI-driven design doesn’t have that constraint. Whether that’s a feature or a terrifying bug depends on what you’re designing.
Part 3 centers on smallpox eradication: 171 years between Jenner’s cowpox demonstration in 1796 and Henderson’s 1967 campaign, and only 10 of those years were spent actually eradicating. Her conclusion is that the bottleneck wasn’t tech, it was coordination and political will, so even if AI drives the marginal cost of biology research to zero, we shouldn’t expect cures to deploy themselves.
2. RAND and Helena on AIxBio mitigations
RAND and Helena released the conference proceedings (full PDF here) from a January 2026 workshop on AI-enabled biological threats. 22 participants from frontier labs, biotech, biosecurity, and academia, working over two days in DC under Chatham House rules, with three threat scenarios: a millenarian nonstate group releasing a novel influenza A, an agroterrorism scenario targeting US wheat with an engineered fungal pathogen, and a state-sponsored insider attack on a semiconductor plant using a biofilm-forming bacterium. Scenarios were deliberately compressed and the document withholds specifics for infohazard reasons.
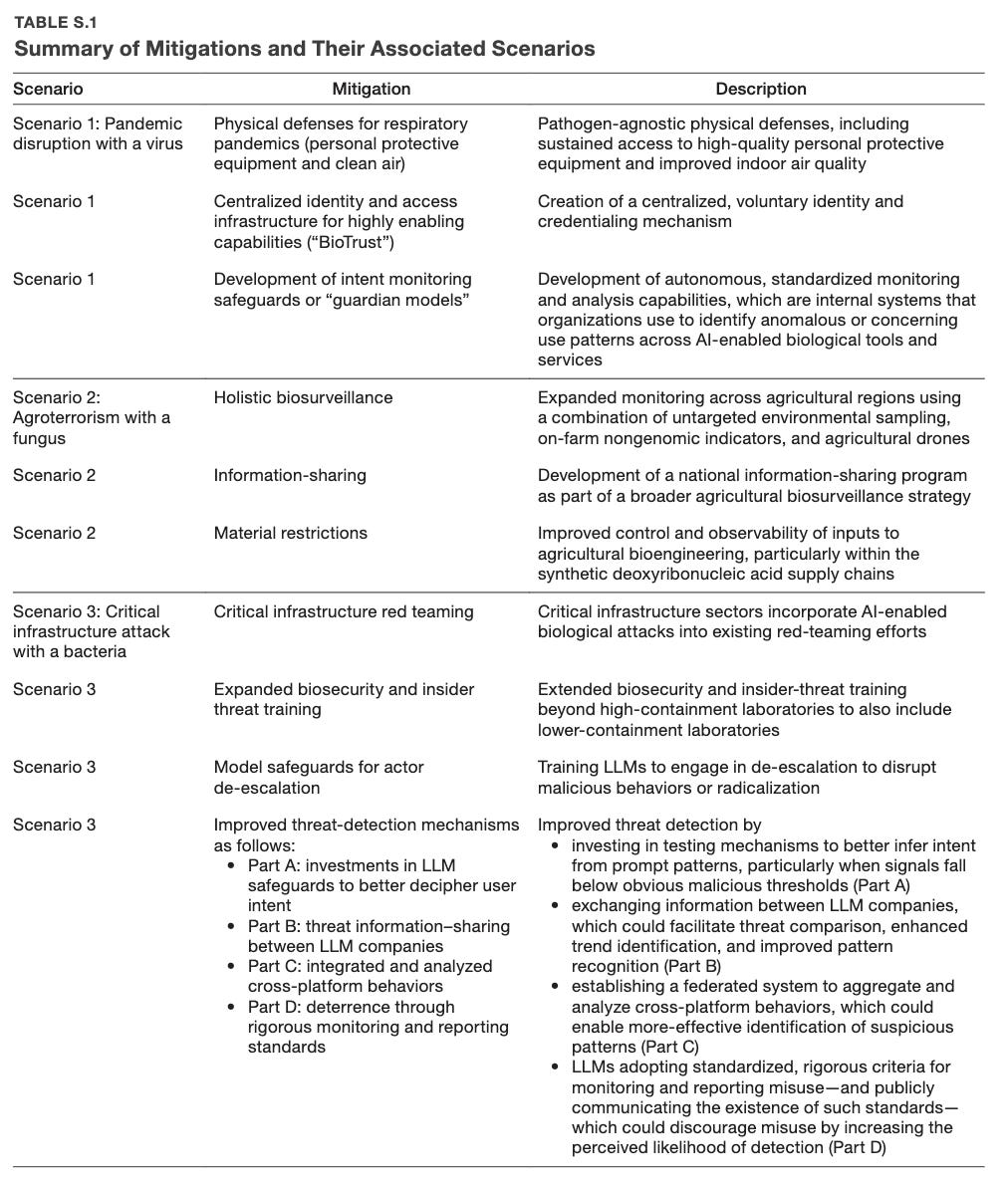
The pandemic group prioritized pathogen-agnostic physical defenses (high-quality PPE, indoor air quality with filtration and UV), a voluntary credentialing system called “BioTrust” modeled on ORCID, and AI “guardian models” for intent monitoring. The agroterrorism group went after holistic biosurveillance, information-sharing modeled on the Kansas Intelligence Fusion Center, and synthetic DNA screening for agricultural pathogens (which gets less attention than human-pathogen screening, and the participants thought that was the most well-scoped problem of the bunch). The critical infrastructure group went hardest on LLM-side interventions: investing in safeguards to better infer intent from prompt patterns, information-sharing between LLM companies via something like the Frontier Model Forum, federated cross-platform behavior analysis, and (this one is interesting) training LLMs to de-escalate malicious intent by adapting techniques from suicide prevention hotlines.
The participants (which included Twist Bioscience, Anthropic, Microsoft, SecureBio, Los Alamos, and others) kept running into the same wall, which the report names explicitly:
A central theme was that technical feasibility and political backing together determine a mitigation’s success.
I.e., most of these will fail without sustained funding and political will, and almost none of them have either. The other recurring caveat was attribution. AI-enabled biological incidents may remain unattributed indefinitely, which weakens deterrence and complicates response authority.
3. Seven points on AI in genomics
Ran Blekhman ran the University of Chicago’s annual genetics, genomics, and systems biology symposium last week, and turned the speaker lineup into seven points on the current state of AI in genomics.

The whole post is worth reading (<10 minutes). I’m just going to highlight a few.
First, the scaling laws may not hold for DNA. Evo 2 is 40 billion parameters trained on 9 trillion nucleotides spanning every domain of life. But Vishniakov et al. (2025) compared seven genomic foundation models against randomly initialized baselines of matched architecture across 52 tasks. The random baselines often matched or beat the pretrained models. Tang et al. (2025) found that raw one-hot encoded sequences are competitive with learned DNA-LM representations on regulatory genomics tasks. As Alex Lu put it at the symposium, DNA isn’t natural language: low signal-to-noise, vast repetitive tracts, no obvious word or sentence analogs, and sparse functional elements that interact combinatorially across long distances.
Second, Arjun Krishnan’s rule of thumb on benchmarks:
The best model is usually the one that is consistently number 2 in benchmarks across the literature.
Whoever publishes a model also designs the benchmark, and the benchmark almost always flatters the model. A model that’s consistently competitive but rarely first-place is more likely to be genuinely strong than one that wins on the benchmark its own authors built. I’m stealing this.
Third, toward the end, is a succinct rule for trainees using AI tools:
If you can validate what the AI produces, namely, if you can do the task yourself comfortably and check whether the AI did it correctly, then you can probably use AI to do the task. Otherwise, you should probably do it yourself, even if it feels hard.
This is the cleanest articulation of the trainee-and-AI problem I’ve seen. I’ve written about this before, highlighting work from a new colleague and co-author, Arjun Krishnan:

The friction of doing it the slow way is often the friction of actually learning, the “productive struggle” I’ve written about here before. An AI tool that produces output you can’t evaluate is just a black box you’re forced to trust. I’d extend that beyond trainees, frankly.
4. Nature’s AI scientists week, and the editorial pushback
On Tuesday, Nature published three full-length papers on AI scientists, an editorial that hedges, and a comment piece that pushes back. All on the same day.

Ghareeb, A. E. et al. A multi-agent system for automating scientific discovery. Nature 1–3 (2026) doi:10.1038/s41586-026-10652-y.
Aygün, E. et al. An AI system to help scientists write expert-level empirical software. Nature 1–3 (2026) doi:10.1038/s41586-026-10658-6.
Gottweis, J. et al. Accelerating scientific discovery with Co-Scientist. Nature 1–3 (2026) doi:10.1038/s41586-026-10644-y.
Messeri, L. & Crockett, M. J. The uncritical adoption of AI in science is alarming — we urgently need guard rails. Nature 653, 675–676 (2026).
Why AI cannot do good science without humans. Nature 653, 650–650 (2026).
The three papers: Google DeepMind’s ERA, an LLM-plus-tree-search system that discovered 40 novel single-cell analysis methods that outperformed the top human methods on a public leaderboard, and 14 COVID hospitalization forecasting models that beat the CDC ensemble. Google’s Co-Scientist, a multi-agent system built on Gemini that helped identify in vitro–validated drug repurposing candidates for acute myeloid leukemia and (in a now-famous demo) recovered an antibiotic-resistance hypothesis that a Imperial College team had spent a decade developing but hadn’t yet published, in days. And FutureHouse’s Robin, which autonomously proposed enhancing RPE phagocytosis as a strategy for dry AMD, identified ripasudil (a clinically used ROCK inhibitor never previously proposed for AMD) as a candidate, validated it in vitro, then proposed an RNA-seq follow-up that fingered ABCA1 as a possible novel target. All hypotheses, experimental directions, data analyses, and main-text figures in the Robin paper were produced by Robin.
These are real results. With that throat-clearing out of the way—
Then there’s the editorial, “Why AI cannot do good science without humans”, which is mostly anodyne until the closing paragraph:
Scientists should not allow a negative view of AI to drive them away from exploring the possibilities that AI co-scientists might hold for research. Equally, however, they must rise above the din of AI hype and advocate for their own importance, to remind the wider public, funders and fellow researchers that science still needs humanity, and that not every grant proposal need include an AI project.
Again: not every grant proposal need include an AI project.
Once more: not every grant proposal need include an AI project.
I read this as the editorial board, deliberately, on the day they published three papers about AI scientists, telling reviewers and program officers not to use “no AI angle” as a reason to triage a proposal.
The comment piece is more pointed. Lisa Messeri (Yale anthropology) and M. J. Crockett (Princeton psychology) wrote “Uncritical use of AI in science needs reality check”. Some empirical claims: Hao et al. (2026) analyzed 41.3 million papers across biology, medicine, chemistry, physics, materials science, and geology and concluded that AI adoption seems to “induce authors to converge on the same solutions to known problems rather than create new ones.” I wrote about this earlier this year:

Kusumegi et al. (2025) looked at 264,125 papers and found that in LLM-assisted papers, good writing stopped being a useful heuristic for scientific quality. Organization Science audited 6,957 submissions from 2021 to 2026 and found LLM-assisted papers had poorer scientific quality by acceptance rate. The closing argument is about deskilling: cleaning raw data, reading and summarizing the literature, the entry-level grunt work that AI is now offered as a solution for, is also how scientists develop the tacit knowledge needed to supervise AI-assisted workflows. If trainees don’t develop those skills, who oversees the AI?

Three papers showcasing autonomous discovery, an editorial gently telling reviewers not to fetishize AI angles in proposals, and a comment piece arguing that the productivity gains may be hollowing out the next generation. Read them together. Or, if you don’t have time, listen to Nature’s podcast.
5. 45 expert scientists review the reviewers
One more, and this connects to a paper I co-authored. A preprint went up at arXiv:2605.20668 titled “On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists.” Big study. 45 domain scientists annotated reviews of Nature-family papers, comparing official human reviewers against three frontier LLM agents. Headline results:
On aggregate review-item quality, all three AI reviewers exceed the lowest-rated human, and GPT-5.2 exceeds the top-rated human.
AI reviewers raise more significant items but with lower correctness.
Replacing one human reviewer with one AI reviewer minimally erodes panel diversity, because human reviewers themselves surface largely disjoint sets of criticisms.
AI reviewers can augment but not replace a human panel.
Current frontier AI reviewers in an agentic framework provide genuine value on the rigor- and code-heavy aspects of peer review, while systematically failing on the field-context aspects.
On that last point: it’s the same argument that Agnieszka Swiatecka-Urban, Arjun Krishnan, and I argued for in our preprint earlier this year.

Our claim was that AI is best deployed as a rubric enforcer for the systematic, criterion-checkable parts of review (consistency between scores and comments, statistical reporting, completeness of evaluation, internal consistency of reviewer reasoning) while humans retain authority on the parts that depend on argumentative-world knowledge (novelty, feasibility, recognizing creative leaps, judging whether an ambitious proposal might fail spectacularly or succeed brilliantly). The arXiv paper, working with a completely different methodology and 45 domain scientists doing item-level annotation of real Nature-family reviews, lands in the same place. AI is strong on rigor and code, weak on field context.