
Structured AI Integration as Quality Control for Peer Review
Decades of research shows that inter-rater reliability is low in grant/manuscript reviews. A new paper presents a case for institutional AI integration in peer review.
A few weeks ago I wrote about the idea that AI could serve as a rubric enforcer in peer review, reducing the variability introduced by fatigue, mood, and ordering effects while preserving the domain expertise that makes review valuable.

Related, late last year I wrote about how unregulated individual adoption of AI in review can introduce its own biases when reviewers selectively prompt and cherry-pick AI outputs.

A new preprint I co-authored with Agnieszka Swiatecka-Urban (UVA School of Medicine) and Arjun Krishnan (CU Anschutz), now available on SSRN, develops these arguments more fully, with a particular focus on AI as a quality control and consistency tool for peer review.

The paper surveys decades of research documenting low inter-rater reliability in both manuscript and grant review, all of which supports the idea that reviewer assignment rather than scientific merit was the primary driver of outcomes.
At the same time, the peer review system is under enormous structural pressure. Submission volumes continue to grow, reviewers are overburdened, and editors increasingly struggle to find willing reviewers. I see us entering a self-reinforcing cycle in which declining review quality encourages more speculative submissions, further taxing an already strained system.
Against this backdrop, recent large-scale studies show that AI systems achieve very high concordance with human reviewers when evaluation criteria are explicit, and that structured AI feedback improved review quality in the vast majority of assessed cases in a randomized trial.
The paper proposes a framework distinguishing where AI can help (systematic rubric-based evaluation, quality control of the reviews themselves) from where human judgment remains essential (novelty assessment, feasibility, recognizing creative leaps). Surveys of researchers themselves support this kind of complementary model over full automation.
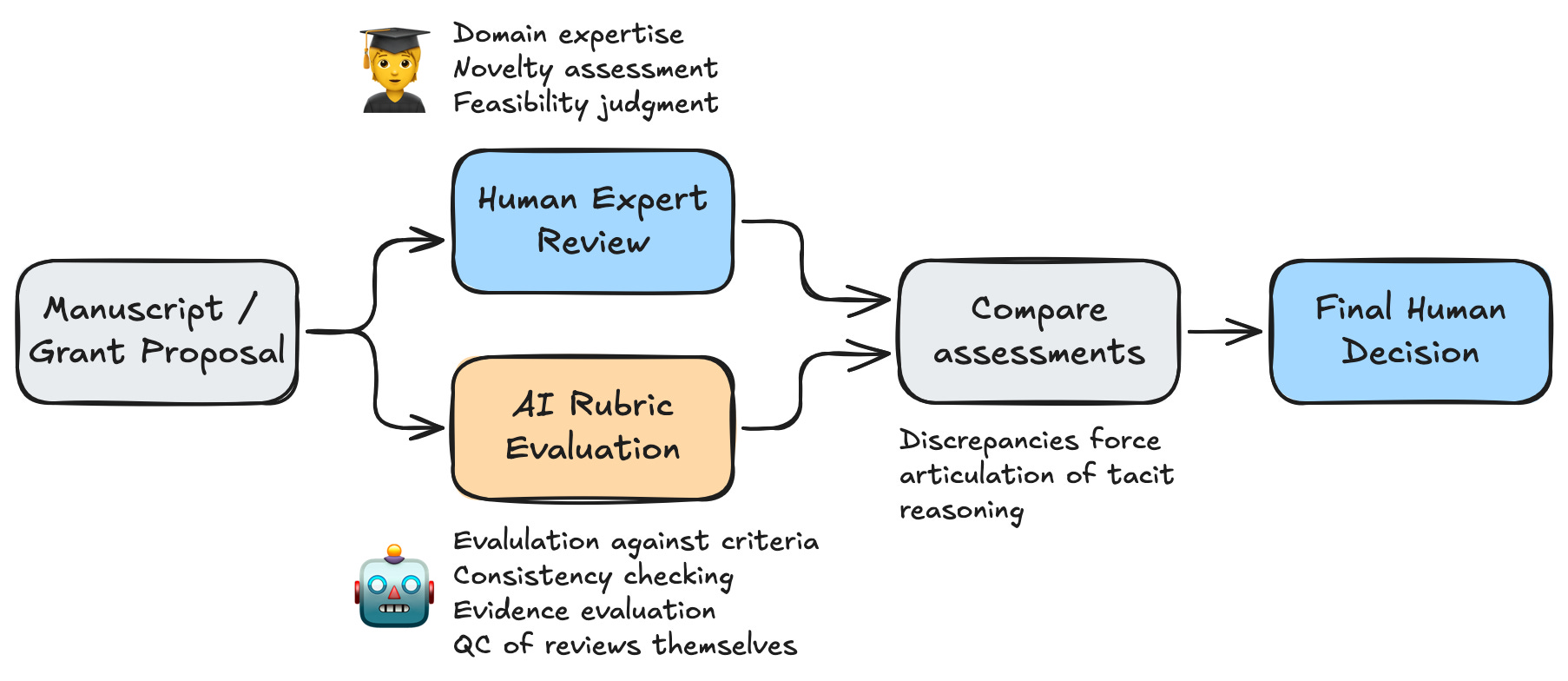
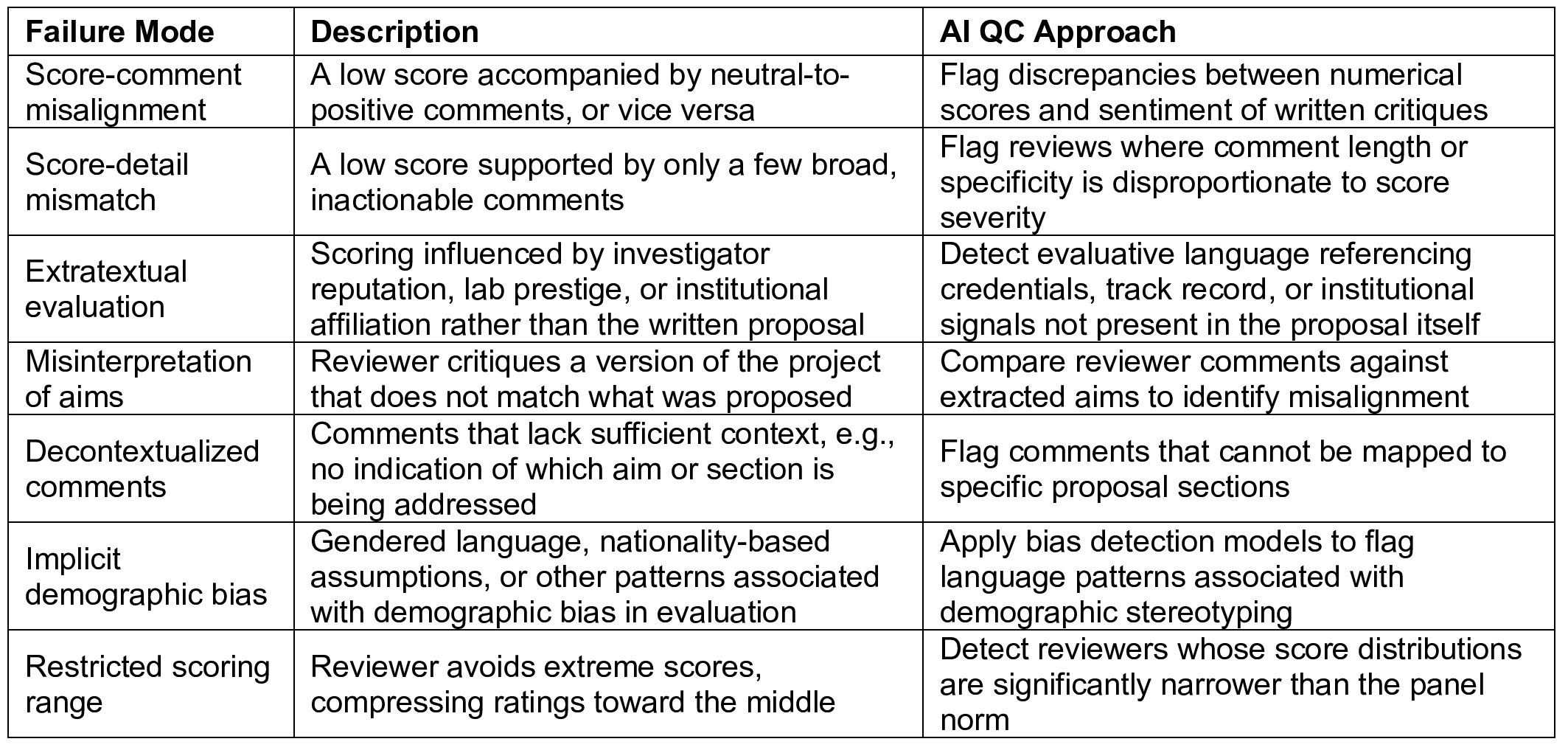
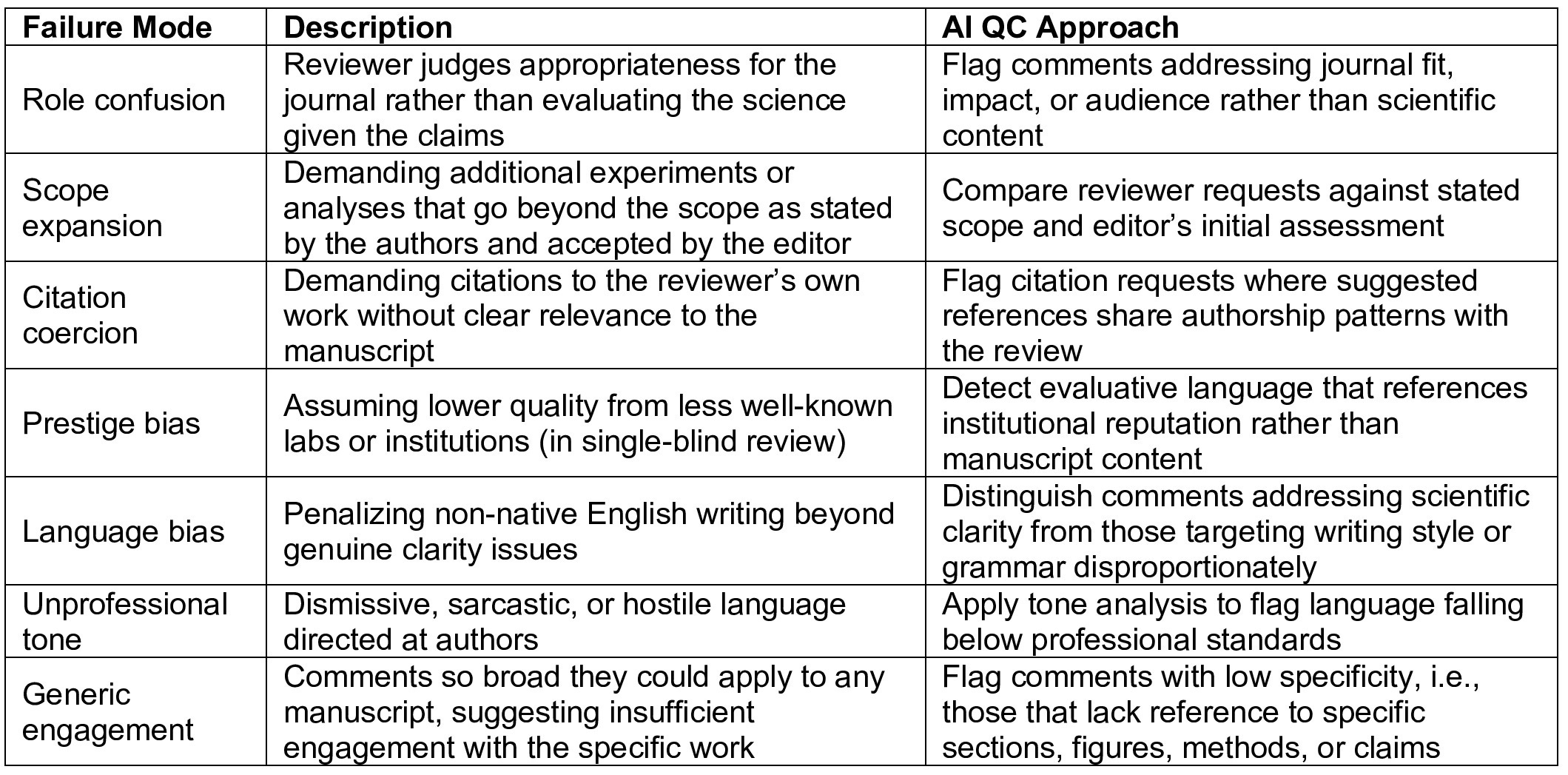
The paper includes two supplementary tables cataloging common failure modes in grant and manuscript review that are amenable to AI-assisted quality control, from score-comment misalignment and implicit demographic bias to citation coercion and unprofessional tone, along with specific AI approaches for flagging each one.
We also genuinely engage with the risks, including confidentiality concerns, automation bias, gaming, and the worry that AI tools give overcommitted reviewers an excuse to skip the hard cognitive work of actually reading the manuscript. AI is a useful tool, but we try to be honest about the limitations.

You can read the full paper here. Citation details below. The paper is in peer review right now. I’d welcome any thoughts or comments you have (after you read the paper, not just the title/abstract). You can leave a comment here or find me on Bluesky.
Turner, S., Swiatecka-Urban, A., & Krishnan, A. (2026). Rubrics, Not Vibes: Structured AI Integration as Quality Control for Peer Review. Social Science Research Network 6314421. https://doi.org/10.2139/ssrn.6314421