
Weekly Recap (March 27, 2026)
NSF AI readiness, AGI forecasts, White House AI policy framework, NIH genomics technology, statistical rethinking, context anchoring, R+Quarto, NOFO graveyard & grant terminations, organ sacks, YYiki.
NSF launched TechAccess: AI-Ready America, a new initiative to fund AI-readiness Coordination Hubs in every U.S. state and territory. Each hub will connect partners across education, workforce development, industry, and government to expand AI literacy, training, and adoption support, with particular attention to small businesses and local government. Round 1 will fund 10 hubs at $1M/year for three years, with one proposal allowed per institution. Other links: Announcement · Funding opportunity · Solicitation (NSF 26-508), two webinars: an introductory session on April 14 and a Q&A on April 23.
Artificial General Intelligence Forecasting and Scenario Analysis. This report from Sarma, Bhatt, Jacob, and Steratore at the RAND Corporation Center on AI, Security, and Technology (CAST) synthesizes the current state of AGI timeline forecasting across expert surveys, prediction markets, compute-centric models, and trend extrapolation, finding that estimates have compressed toward the 2030s across independent methods while the infrastructure for validating those forecasts remains thin. The report describes a taxonomy of three “cruxes” driving disagreement (scaling sufficiency, diffusion speed, takeoff dynamics) and its argument that forecasts should be treated as scenario-structuring tools rather than point predictions. There’s an interesting disclosure here: the report was primarily drafted by LLMs (GPT-5.1, Gemini 3 Pro, Claude 4.5 Opus) with human direction and fact-checking, and the authors are candid about the recurring citation errors and factual inaccuracies they had to correct in the AI-generated drafts. Maybe the disclosure itself made me extra sensitive to all the LLM tells—it’s not X it’s Y, em dashes everywhere, and tricolons like this one.
The White House released their National Policy Framework on AI. The move that shouldn’t surprise anyone here is federal preemption of state AI laws: the framework explicitly calls for barring states from regulating AI development, which it frames as inherently interstate with national security implications. Beyond preemption, the document covers child safety (parental controls, age-assurance requirements), energy (residential ratepayers shouldn't bear data center electricity costs), IP (the administration believes training on copyrighted material is fair use but says courts should resolve it), and an anti-censorship provision aimed at preventing government from coercing AI providers on content. Notably absent: any new federal regulatory body for AI. The framework explicitly says Congress should not create one, relying instead on existing sector regulators and industry-led standards.

Technology Development for Genomics. A new NIH highlighted topic (open through August 2026) signaling investigator-initiated applications are welcome for new methods in sequencing, epigenomics, functional genomics, multiomics, spatial/temporal resolution, direct RNA/DNA sequencing, oligo synthesis, and high-throughput phenotyping of genetic perturbations. Participating ICOs include NHGRI, NIAID, NCI, NHLBI, and others. Not a specific funding opportunity announcement, but a signal of what program officers want to see come through the parent R01/R21 mechanisms. Particularly relevant context given the OMB hold on NIH spending just lifted this week; if new grants are about to start flowing again, knowing what the institutes are hungry for matters.

Posit: Working with Jupyter Notebooks in Positron.
UVA SDS Story of Us: Chapter 4: A Growing School. The latest chapter of UVA’s institutional history of its School of Data Science, covering 2024 to the present. The throughline is a school reaching institutional maturity: first PhD graduates hooded, a retooled master’s curriculum, an inaugural undergraduate class of 75 (now 125), a second building approved for design, and our faculty and staff growing from 30 to over 100. The chapter closes with the death of founding dean Phil Bourne earlier this month. Phil’s legacy is woven throughout, from insisting his office be no larger than any other faculty member’s to spearheading UVA’s Futures Initiative on AI in higher education. When asked what he was most proud of, Phil answered immediately: “Everybody.” A fitting capstone for a school that didn’t exist a decade ago. Phil’s memorial service was live streamed last week, and the recording is available here.
Richard McElreath released lecture recordings and notes from his course, “Statistical Rethinking.” The course focuses on logical and critical statistical workflows, from basic probability theory to causal inference to reliable computation to sensitivity.
Rahul Garg: Context Anchoring. Part of an ongoing “Reducing Friction” series on martinfowler.com, this one argues that developers cling to long AI coding sessions not because they’re productive but because the decision context lives nowhere else. The proposed fix is a lightweight “feature document” that externalizes the why behind decisions (not just the what), functioning as a living Architecture Decision Record (ADR) that lets you kill a session and cold-start a new one in 30 seconds. If closing your chat window makes you anxious, your context isn’t properly anchored.

Matt Lubin Five Things: March 22, 2026. Politicians, security breaches, OpenFold3, the AI “consciousness cluster”, dog’s cancer cured? As always, Matt provides a great recap of things happening in the world of AI/biosecurity and related topics over the past week, and it’s one of the weekly newsletters I look forward to the most.
Charlotte Wickham: Quarto 1.9. The highlights for me: Typst now supports book projects and article layouts with margin content, there’s experimental PDF accessibility compliance for both LaTeX and Typst, and websites can generate llms.txt output so LLMs can read your docs cleanly. More on accessibility via alt text, and automating it with Claude Code:

Elizabeth Ginexi: The NOFO Graveyard. A former NIH program officer (22 years) responds to NIH Deputy Director Jon Lorsch's blog post defending the agency's reduction in Notices of Funding Opportunities. Ginexi compiled 14 years of NOFO data: NIH averaged ~724 NOFOs per year in 2023–2024, posted 120 in 2025 (an 83% decline, not the mandated 50%), and is on pace for far fewer in 2026. Of 271 opportunities forecasted in 2025, only 120 were ever posted. Lorsch's claim that fewer NOFOs wouldn't mean fewer funded applications is contradicted by NIH's own data showing R01-equivalent awards fell 20% in a single year. Ginexi argues the real administrative burden on program staff isn't NOFO management but politically motivated grant screening, and that centralizing NOFO approval through NIH/OD, HHS, and OMB transfers scientific priority-setting from domain experts to political appointees.
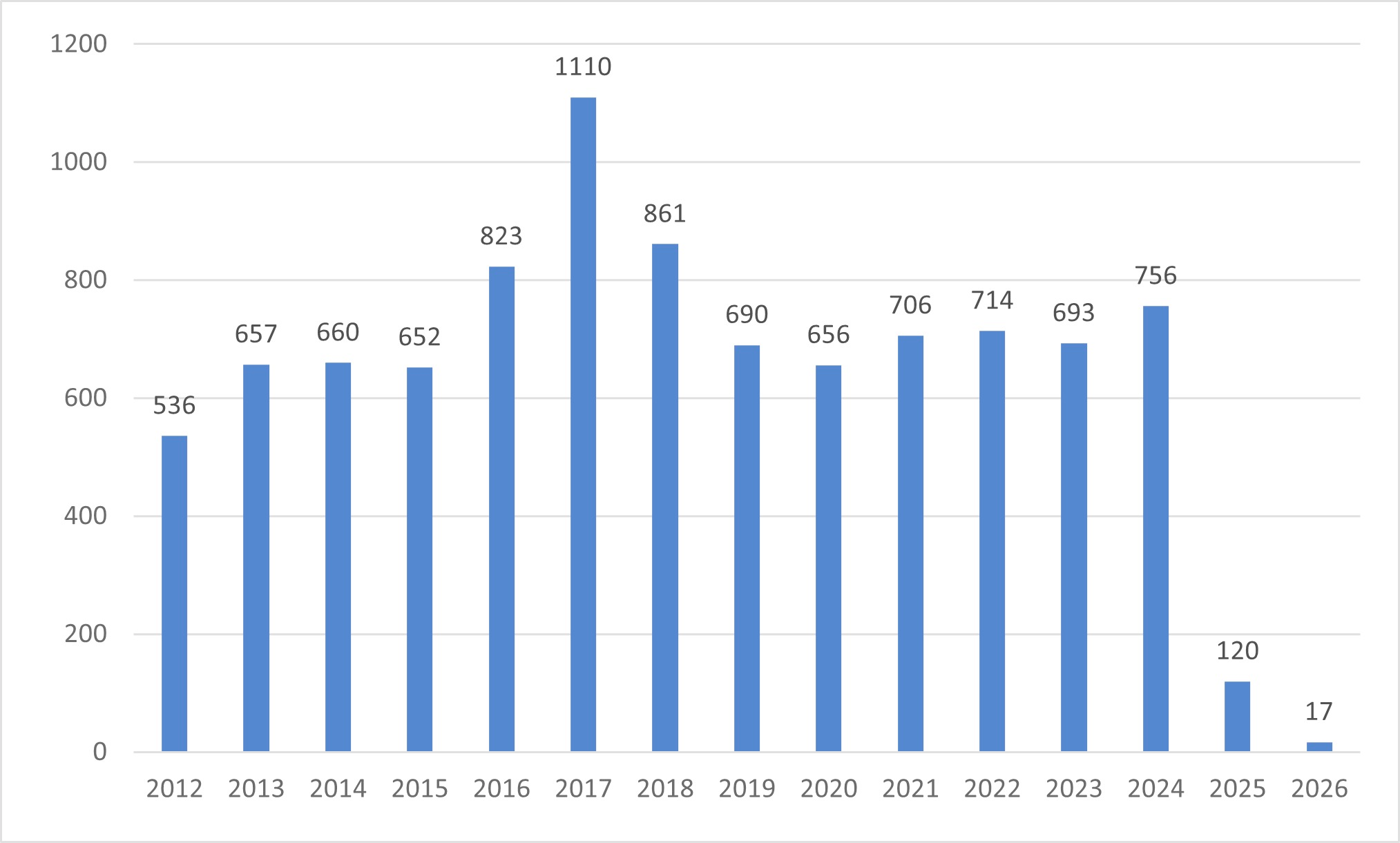
Proteina-Complexa. NVIDIA's new protein binder design framework unifies generative modeling and hallucination-style optimization under one roof, using flow-based latent generation with test-time compute scaling. Over a million binder candidates screened across 133 targets yielding 63.5% hit rates on PDGFR with picomolar affinities and the first-ever de novo designed carbohydrate binders. Self-generated sequences outperformed ProteinMPNN redesign across the board, which, if it holds up broadly, is a shift away from the two-stage generate-then-redesign paradigm.
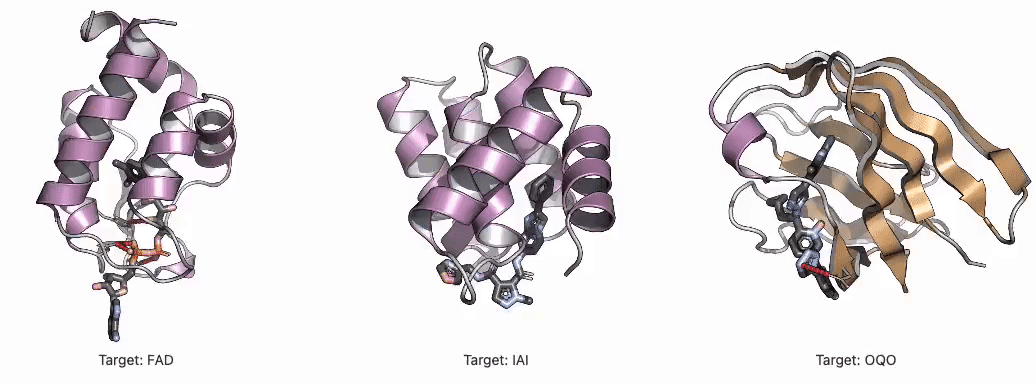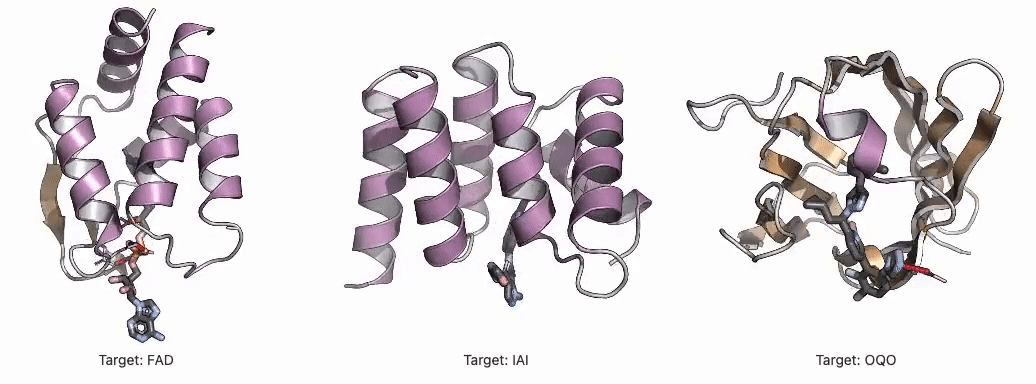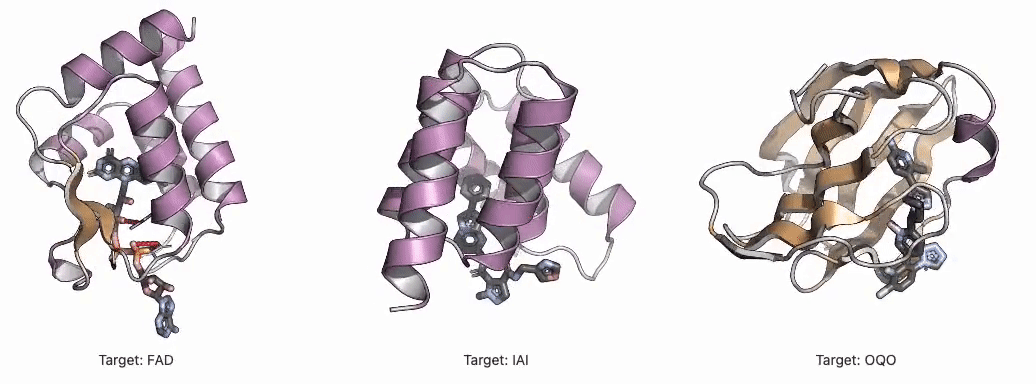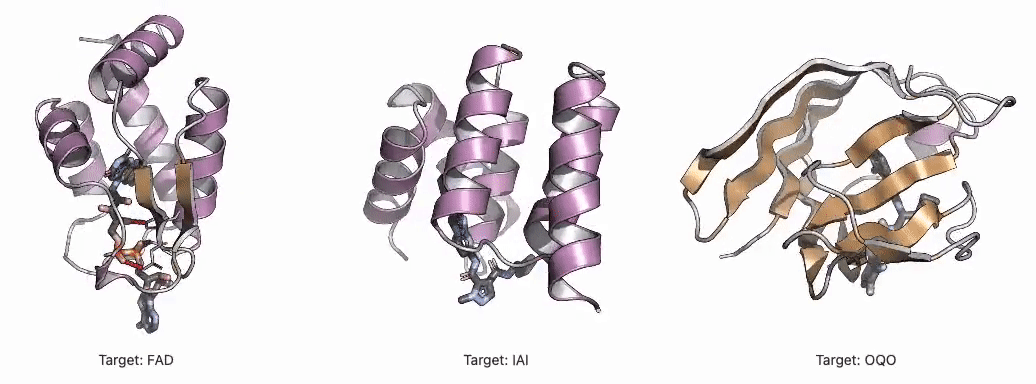
R Weekly 2026-W13: What’s new in dplyr, Atmospheric simulation.
Simon Willison: Using Git with Coding Agents. A chapter from Willison's growing “Agentic Engineering Patterns” guide. You don’t need to memorize Git's more arcane commands anymore, but you do need to know what's possible so you can ask for it. Good bits on using git log to seed a fresh agent session with recent context, and on how agents turn git bisect from a tool most developers avoid into something you'd reach for casually.
Diego Oliveira, Qian Huang, Teresa Woodruff, and Brian Uzzi: How the 2025 NIH Grant Terminations Varied by Researchers' Demographic Groups. A PNAS brief report documenting who got hit by the 2025 NIH terminations: 2,291 grants, $2.45 billion rescinded, with 52% of allocated funds already spent at the time of cancellation. Early-career investigators and women were disproportionately affected. Among assistant professors, 59.8% of terminated projects were women-led. Women's grants were smaller on average ($940K median vs. $1.4M for men) but had a larger share of unspent funds at cancellation (57.9% vs. 48.2%), meaning more ongoing work was interrupted per dollar. Training and transition awards (F31s, F30s, T34s) were frequently cut. The authors estimate $6.29 billion in unrealized economic output using standard NIH multipliers, though they're careful to frame that as a benchmark rather than a verified loss.
Emily Mullin, WIRED: A Billionaire-Backed Startup Wants to Grow ‘Organ Sacks’ to Replace Animal Testing. R3 Bio, a Bay Area startup backed by Tim Draper and a Singapore longevity fund, is pitching the idea of growing brainless primate (and eventually human) “organ sacks” as replacements for lab animals. The concept: use stem cells and gene editing to grow organized organ structures that lack any brain tissue, making them incapable of sentience or pain. The near-term application is drug toxicity testing in monkeys at a time when US primate supply is constrained after China’s 2020 export ban. The longer-term ambition is growing human organ sacks as a source of transplant organs. The company says it’s currently only working in monkey cells, though a job posting seeks a veterinarian in Puerto Rico to implant embryos in nonhuman primates. The science is plausible according to UC Davis stem cell biologist Paul Knoepfler, but everything about this is still highly theoretical, and a Stanford bioethicist notes the “yuck factor will be strong.”
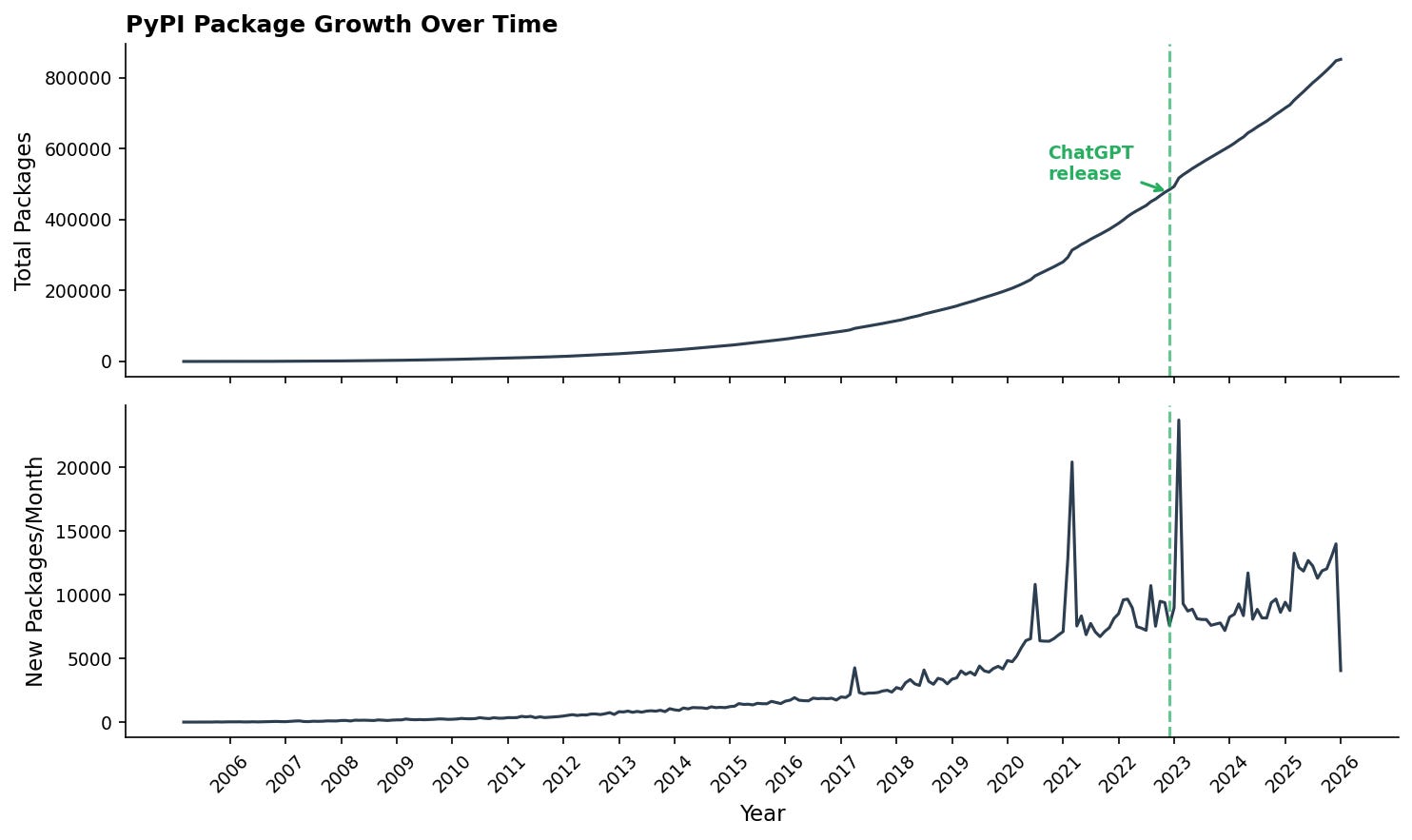
Alexis Gallagher and Rens Dimmendaal: So Where Are All the AI Apps?. If AI coding tools make developers 2x (or 10x, or 100x) more productive, you should be able to see it in PyPI package creation and update rates. The authors looked, and mostly didn’t see it. Total package creation shows no inflection at ChatGPT’s release. Update frequency for the top 15,000 packages shows a modest secular trend that predates AI tools. The one place a clear >2x effect does appear: popular packages about AI, which jumped post-ChatGPT compared to popular non-AI packages. The authors’ two candidate explanations are that AI-tool builders are the ones most skilled at using AI to build (a skill effect), or that the flood of money into AI is simply paying for more work on AI packages (a funding effect). Probably both, but the data can’t distinguish them. Either way, the Cambrian explosion in all software hasn’t materialized; the measurable effect is concentrated in the AI ecosystem building tools for itself.
Ryan Wright and Varun Korisapati , at AI Exchange @ UVA Substack: State of AI in the Commonwealth: Teaching & Learning with AI. Part of a rolling series from UVA’s Center for Management IT drawing on nearly 200 sources to map AI’s impact in Virginia. This installment focuses on education, and the most useful data point comes from a McIntire study of 356 students across 6 conditions: the best learning outcomes came from group work paired with a custom RAG tutor, while generic chatbots performed worst. The broader numbers frame the context: the global AI-in-education market jumped 46% in a single year (to $7.57B in 2025), 61% of faculty report using AI in teaching, but 88% of those describe their use as minimal.
And a recommendation: My SDS colleague YY Ahn maintains a public wiki that sits somewhere between a research notebook, a tool log, and a blog. It’s updated frequently and worth browsing if you’re into academic workflows, network science, or the ongoing project of making AI tools actually useful for research. A few recent entries: Claude Scholar plugin, a set of Claude Code skills for academic work (arXiv metadata fetching, BibTeX from DOIs, math verification via SymPy, pre-submission LaTeX checks); How I Use Claude Code, a living document on his terminal/editor/dictation setup; paper notes on topics ranging from LLMs inferring political alignment from conversations to community-centric citation dynamics; and a separate urbanism thread with entries on topics like the true cost of car ownership (read this one!). The whole thing runs on a kind of accumulating-notes-in-public model that I bookmark whenever I find them.
New papers & preprints:
Generalist biological artificial intelligence in modeling the language of life
LLMs Can Infer Political Alignment from Online Conversations
LazySlide: accessible and interoperable whole-slide image analysis
ProteinMCP: An Agentic AI Framework for Autonomous Protein Engineering
LLM agents for biological intelligence across genomics, proteomics, spatial biology, and biomedicine