
Weekly Recap (March 20, 2026)
NIH NOFOs, bioRxiv, AI+writing pod, Astral+OpenAI, AI in VA, AMLC, DARPA bioattribution, future of biosecurity, AI talent at universities, brain fry, AI+bioinformatics, R updates, agentic engineering.
Elizabeth Ginexi: I Wrote Research Funding Announcements for NIH for 22 Years. This Year They’ve Published 14. How NIH went from 756 funding announcements to 14 in two years and what it means for every disease that depends on federal research.
Ryan Wright and Varun Korisapati at AI Exchange @ UVA Substack: AI Exchange @ UVA Podcast with Piers Gelly and T. Kenny Fountain, faculty members in the University of Virginia’s Department of English, discussing how generative AI is reshaping the teaching and practice of writing. Piers Gelly wrote a fantastic essay last year, “What Happened When I Tried to Replace Myself with ChatGPT in My English Classroom” and if you haven’t read it yet, I recommend it.
How bioRxiv changed the way biologists share ideas. A Nature news piece pegged to a new analysis from the openRxiv team marking bioRxiv's first 13 years: 310,000+ preprints posted, 4 million downloads a month, and 80% of preprints eventually published in journals. The survey data on why researchers post (visibility, priority, feedback) is a useful corrective to the outdated assumption that preprints are a workaround for researchers with something to hide.
More from Ryan Wright and Varun Korisapati at AI Exchange @ UVA Substack: Exploring AI Readiness in Virginia. Big Question: Are we preparing every Virginian, not just technologists, to thrive in an AI-enabled economy? AI literacy is still uneven and demand is rising faster than readiness.
Charlie Marsh, Astral: Astral to Join OpenAI. Astral, the company behind Ruff, uv, and ty (tools that have become close to default infrastructure for modern Python development), is being acquired by OpenAI and will join the Codex team. Marsh writes about this as a natural extension of the mission to make programming more productive, now at the frontier where AI meets developer tooling. OpenAI says it will continue supporting the open source tools, and Astral says they'll keep building in the open. The obvious question for anyone who depends on uv or Ruff is whether “continue supporting” holds up once Astral's attention is split between maintaining open source Python tooling and building product for OpenAI's coding agent. Worth watching closely.
Job ad: arXiv CEO. arXiv is becoming an independent (nonprofit) company and they're looking for a CEO. Salary $300,000.
RAND Europe: Cost-Benefit Analysis for Synthetic Nucleic Acid Screening in the European Union. The first EU-level quantitative CBA comparing three policy pathways for DNA synthesis screening: voluntary guidance, conditionality tied to research funding, and mandatory regulation under the proposed Biotech Act. The headline finding is that mandatory screening yields about €4.6 billion in average annual net benefits over ten years, with a 6:1 return on costs, driven largely by the non-linear relationship between screening coverage and risk reduction. The report was partly funded by Sentinel Bio, and the cost estimates are described by the authors themselves as conservative, with real-world screening costs potentially 75% lower than modeled.

Schedule Released: 2026 Applied Machine Learning Conference. Friday, April 17 features keynotes from David Luebke (Co-founder of NVIDIA Research) and Vicki Boykis (founding ML engineer at Malachyte), plus four tracks of talks from speakers at organizations like Anthropic, Amazon, Microsoft, McAfee, S&P Global, DARPA, IBM, PagerDuty, and many more, as well as leading universities including UVA, Virginia Tech, Duke, and NC State. Saturday, April 18 is all hands-on, with three tracks of 90-minute tutorials that dive deeper into topics such as building production-grade AI agents, agentic search, knowledge graph construction, MCP integration with real databases, probabilistic programming, physics-informed neural networks, and more. Register here (early bird pricing ends today).
Matt Lubin: Five Things: March 15, 2026: Anthropic v. Pentagon latest, human v. LLM text, cybercrime updates, protein production paper, reviews of LLM bio uplift.
Bio-attribution Challenge. DARPA's Biological Technologies Office is running a two-round computational competition with $180K in prizes for teams that can detect and attribute engineered pathogens at petabyte scale in near real-time. No wet lab work involved: all data is LLNL-curated synthetic sequences run in a government-controlled environment, which makes this an accessible entry point for bioinformatics and ML teams who want to work on biosecurity problems without navigating biosafety infrastructure.
Abhishaike Mahajan: Reasons to be pessimistic (and optimistic) on the future of biosecurity. A long, interview-dense survey of the biosecurity landscape covering the disappearing DNA synthesis chokepoint, the surprisingly underappreciated risk of agricultural bioterrorism, and the funding cliff facing BARDA and CDC under the FY26 budget. Abhishaike takes the AI uplift threat seriously while also citing the Active Site RCT (my own blog post on this here) showing that frontier models even with safety classifiers off gave novices no statistically significant advantage over a Google search in a wet lab. Well worth the long read for anyone interested in this space. Pairs naturally with the DARPA bio-attribution challenge above.
Sara Altman + Simon Couch / Posit blog: 2026-03-13 AI Newsletter.
Simon Willison: What is agentic engineering? (It’s not just vibe coding).
Julie Bedard et al: When Using AI Leads to "Brain Fry". A BCG research team surveyed 1,488 U.S. workers and found that intensive AI oversight (not AI use per se) drives acute cognitive fatigue, while using AI to replace repetitive tasks actually lowers burnout scores. The distinction between burnout (emotional exhaustion) and “brain fry” (attentional overload from managing agents, c.f. brain rot) is the useful, even if the prescription (e.g. clearer org communication, holistic job redesign) reads like standard change management advice.

"Shall I implement it?" User says no. OpenClaw thinks for a bit, and decides that the user actually meant yes, do it without asking.
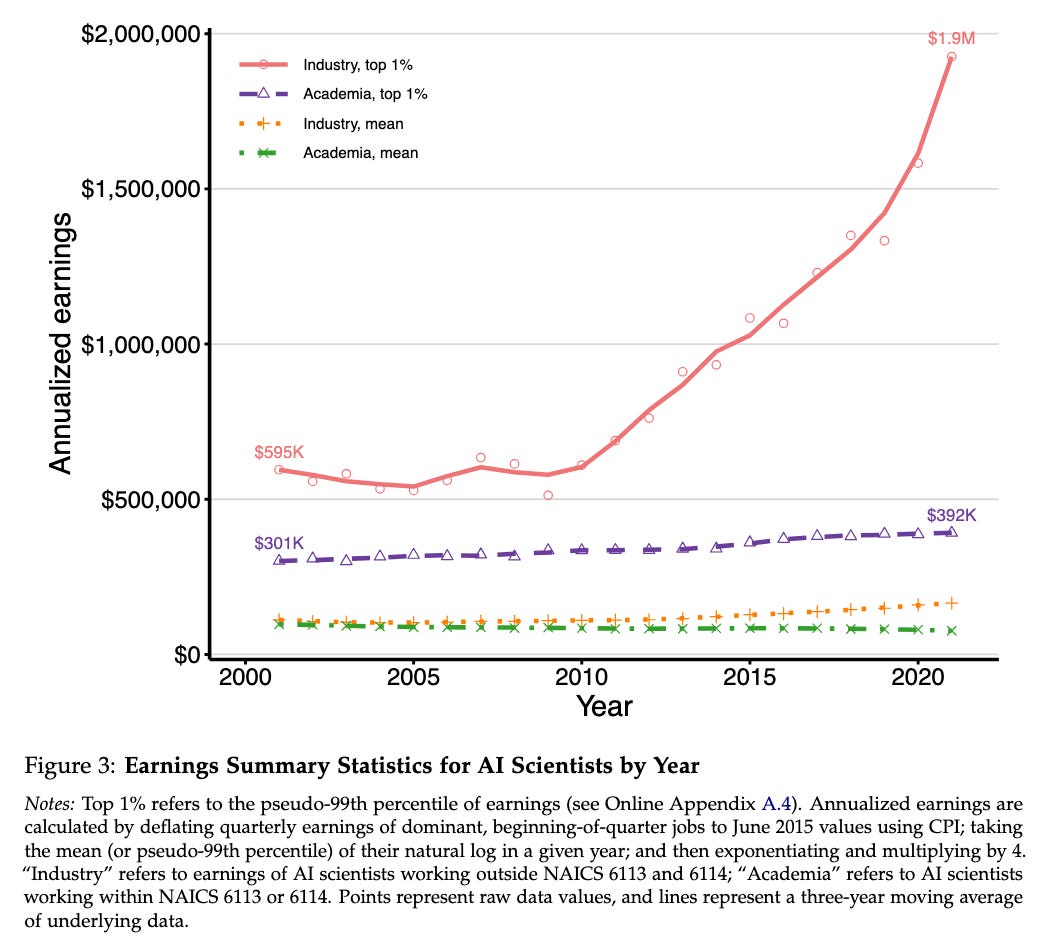
New NBER working paper: Attention (And Money) Is All You Need: Why Universities Are Struggling to Keep AI Talent. “The top 1% of publishing industry scientists now earn $1.5 million more annually than comparable academics, a fivefold increase since 2001.” In one image:
David Adam, Nature Medicine: The AI Co-Scientist Is Here. A survey of where AI-driven hypothesis generation stands in biomedicine right now, anchored by Google’s AI co-scientist tool and Insilico Medicine’s rentosertib (possibly the first fully AI-discovered drug to reach phase 3). An interesting tension in the piece is between the flashy anecdotes (Gary Peltz’s drug repurposing hits, José Penadés’s lab having its unpublished findings independently rediscovered by the model) and the less-flashy caveats: Google won’t say how many testers got less impressive results, the Stanford ideation-execution gap study found human ideas still won after implementation, and LLM-based tools are limited to open-access literature.
R Weekly 2026-W12: Sharing across shiny modules, F1 data.
Isabella Velásquez & Libby Heeren, Posit Data Science Lab: How to use Positron’s GitHub integration.
Nils Homer: Your Bioinformatics Tools Need to be AI-Ready. A sharp argument that bioinformatics tools should be designed from the start to emit rich, structured metadata suitable for ML training, not just the summary QC metrics we’ve been building for human eyeballs. Homer draws on his experience building Picard and fgbio to make the case that the gap between “useful QC output” and “ML-ready feature vectors” is small but real, and that closing it retroactively across thousands of samples is far more painful than doing it right the first time. Nils lays out some design principles:
Observable. Emit structured, semantically rich metadata at every step. Not just final answers, but the evidence trail. Per-read, per-site, per-family, per-molecule. Use well-defined tags, clear column headers, and machine-readable formats.
Composable. Consistent, well-documented interfaces that both humans and AI agents can discover, chain, and reason about. Standard formats. Clear help text. Predictable behavior. Outputs parseable by a post-doc who happens to be an LLM.
Trainable. Feature-rich representations that serve as training data for downstream ML. Emit the features, not just the conclusions.
New papers & preprints: