
Tidy RAG in R with ragnar
Retrieval augmented generation in R using the ragnar package. Demonstration: scraping text from relevant links on a website and using RAG to ask about a university's grant funding.
Note: After I wrote this post last week, the Tidyverse team released ragnar 0.2.0 on July 12. Everything here should still work, but take a look at the release notes to learn about some nice new features that aren’t covered here.
I’ve written a little about retrieval-augmented generation (RAG) here before. First, about GUIs for local LLMs with RAG:

…and later on building a little RAG app to chat with a bunch of PDFs in your Zotero library using Open WebUI:

In an oversimplified nutshell: LLMs can't help you with things that are not in their training data or are past their training cutoff date. With RAG, you can provide relevant snippets from those documents as context to the LLM so that its answers are grounded in a collection of known content from a trusted document corpus.
Even more oversimplified: RAG lets you “chat with your documents.”
In this post I’ll demonstrate how to scrape text from a website and implement a RAG workflow in R using a new addition to the tidyverse: ragnar, along with functionality from ellmer to interact with LLM APIs through R.
Demonstration
Python has historically dominated the AI product development space, but with recent additions like ellmer, chores, gander, and mall, R is quickly catching up.
Here I’m going to use the new ragnar package in the tidyverse (source, documentation) to build a little RAG workflow in R that uses the OpenAI API.
I’m going to ingest information from the UVA School of Data Science (SDS) website at datascience.virginia.edu, then ask some questions that won’t have answers in the base model’s training data.
Setup
If you want to follow along you’ll need an OpenAI API key. You can set that up at platform.openai.com. Once you do that, run usethis::edit_r_environ() to add a new OPENAI_API_KEY environment variable, and restart your R session.
In R I’m going to need the ellmer and ragnar packages. Because ragnar isn’t yet on CRAN, I'll have to install it with pak or devtools.
install.packages("ellmer")
pak::pak("tidyverse/ragnar")Create a vector store
The first thing I want to do is to find all the links to other pages at datascience.virginia.edu, scrape all of that content, and stick it into a DuckDB database. Most of this is modified straight from the ragnar documentation, hence the context chunking still looks like I’m ingesting a book.
library(ragnar)
# Find all links on a page
base_url <- "https://datascience.virginia.edu/"
pages <- ragnar_find_links(base_url)
# Create and connect to a vector store
store_location <- "pairedends.ragnar.duckdb"
store <- ragnar_store_create(
store_location,
embed = \(x) ragnar::embed_openai(x),
overwrite=TRUE
)
# Read each website and chunk it up
for (page in pages) {
message("ingesting: ", page)
chunks <- page |>
ragnar_read(frame_by_tags = c("h1", "h2", "h3")) |>
ragnar_chunk(boundaries = c("paragraph", "sentence")) |>
# add context to chunks
dplyr::mutate(
text = glue::glue(
r"---(
# Excerpt from UVA School of Data Science (SDS) page"
link: {origin}
chapter: {h1}
section: {h2}
subsection: {h3}
content: {text}
)---"
)
)
ragnar_store_insert(store, chunks)
}
# Build the index
ragnar_store_build_index(store)Retrieval
Now suppose we want to ask questions about research grant funding at the UVA School of Data Science (SDS). First, let’s see what ChatGPT tells us without providing any context at all when we ask it to tell us about SDS’s active grant funding.
I don’t have specific information about “SDS’s active grant funding” because “SDS” could refer to several different organizations or entities (e.g., Social and Decision Sciences departments, Sustainable Development Solutions, Students for a Democratic Society, or a company with the acronym SDS).
Now let’s use the OpenAI API providing context from the vector store we just created that should have information about UVA SDS’s active funding from their active grants listing page.
library(ragnar)
store_location <- "pairedends.ragnar.duckdb"
store <- ragnar_store_connect(store_location, read_only = TRUE)
# Get relevant chunks
text <- "Tell me about some of SDS's active grant funding."
relevant_chunks <- ragnar_retrieve_vss(
store,
text,
top_k = 10
)
relevant_chunks
#' Register ellmer tool
#' You can register an ellmer tool to let the LLM retrieve chunks.
system_prompt <- stringr::str_squish(
r"--(
You are an expert about UVA's School of Data Science.
You are concise. You always respond by first direct
quoting material from the SDS website, then adding
your own additional context and interpertation.
Always include links to the source materials used.
)--"
)
chat <- ellmer::chat_openai(
system_prompt,
model = "gpt-4.1-mini",
params = ellmer::params(temperature = .5)
)
# Register a retrieve tool with ellmer
ragnar_register_tool_retrieve(chat, store, top_k = 10)
# Run the query
chat$chat(text)Now when asking about some of SDS’s active grant funding, we get a better response:
Here are some examples of active grant funding at UVA's School of Data Science (SDS):
Resource and Data Exchange (RDE) has a grant award of $5,000,000 with a performance period from Feb 29, 2024 to Feb 27, 2029, currently 25% completed.
Biomedical Data Science Innovation Labs: An Intensive Research Project Development Program has an award amount of $1,943,352.
Supporting Pre-Service Teachers Mathematical Discourse through Co-Design of Teaching Simulation Tools is sponsored by the US NSF with a total award of $250,000.
Activity Aware Bayesian Deep Learning is sponsored by the US NSF.
Enhancing Security and Privacy of Community Cyberinfrastructures for Collaborative Research has a total award of $882,518 from the US NSF.
Evaluating the Efficacy of Repurposed Medications has an award amount of $86,134.
Accelerating racial and ethnic equity in SCI rehabilitation outcomes has an award amount of $53,170.
The application of data science on financial systems with an emphasis on safety and security has an award amount of $5,000.
These grants cover a range of topics from education, biomedical innovation, security, to social equity in rehabilitation.
Source: UVA SDS Active Grants
API cost and local models
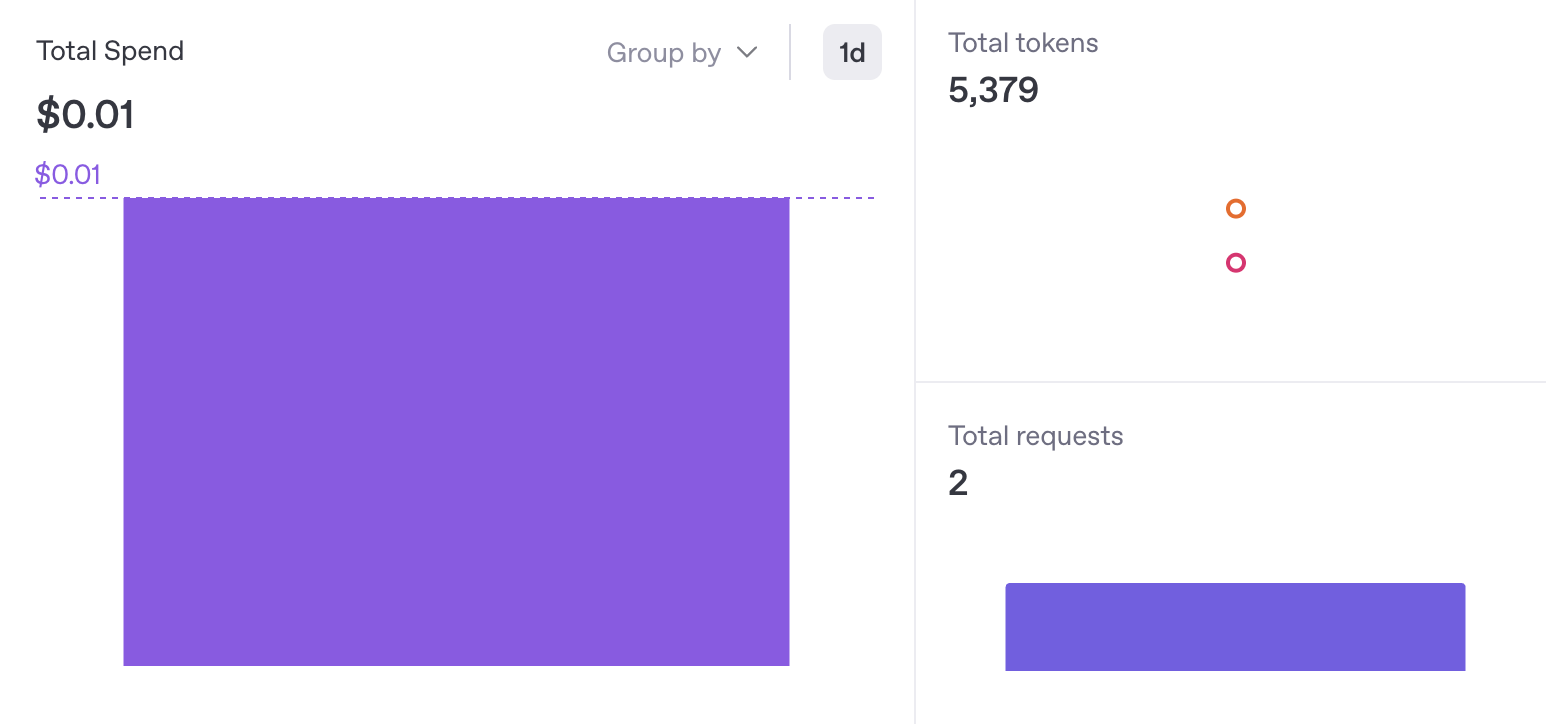
As I’m writing this, the cost for GPT-4.1 mini is ridiculously cheap at $0.40 cents per million input tokens (see more on their API pricing page). The demonstration here cost me $0.01 cent (the text embedding and vector storage cost a fraction of a penny in addition to the input/output completions).
There are plenty of open/local models that support tool use, as well as open/local text embedding models, all of which can be run through Ollama. I tried the same exercise above using Nomic Embed through Ollama for text embedding, and tried several with tool calling abilities, including qwen3, mistral, llama3.1, llama3.2, llama3.3, and the new llama4, and the results were all terrible. I don't know if this was due to the inferiority of the models themselves, or if this was the embedding model that I chose, which incidentally happened to be the most popular embedding model available in Ollama. Just put $1 on your OpenAI API account and get to work and stop worrying about it.
Learning more
This recent webinar from Posit CTO Joe Cheng doesn’t cover RAG at all. In fact, he mentions near the top that RAG should not be your first choice when simply changing a system prompt would be good enough. It’s a good talk and I learned a few nice things along the way.