I started blogging 17 years ago, and the most common question I get from colleagues and students is how do you stay current and find all these interesting papers/blogs/etc.? I wrote this post in 2012 and followed it up 5 years later with this post in 2017 on staying current in bioinformatics and genomics. The 2012 post was very focused on RSS feeds, and the 2017 post was very heavy on Twitter accounts. The death of Google Reader in 2013 and the concurrent social mediafication of the web made RSS fall by the wayside during these intervening years. Since the 2017 post, Twitter has become unusable for scientific discourse. Many of the accounts I suggested back then are inactive or deleted.
Thankfully there seems to be a resurgence of interest in long-form blogging, and even though RSS was long pronounced dead, it’s still very much alive and well if you know how to use it. And of course we have the rise of AI tools that can help with discovery, curation, and summarization.
So, following the 2012 and 2017 posts, what follows is a scattershot, noncomprensive guide to the people, blogs, news outlets, journals, and aggregators that I use to stay on top of things (with apologies for any inevitable omissions).
Journals
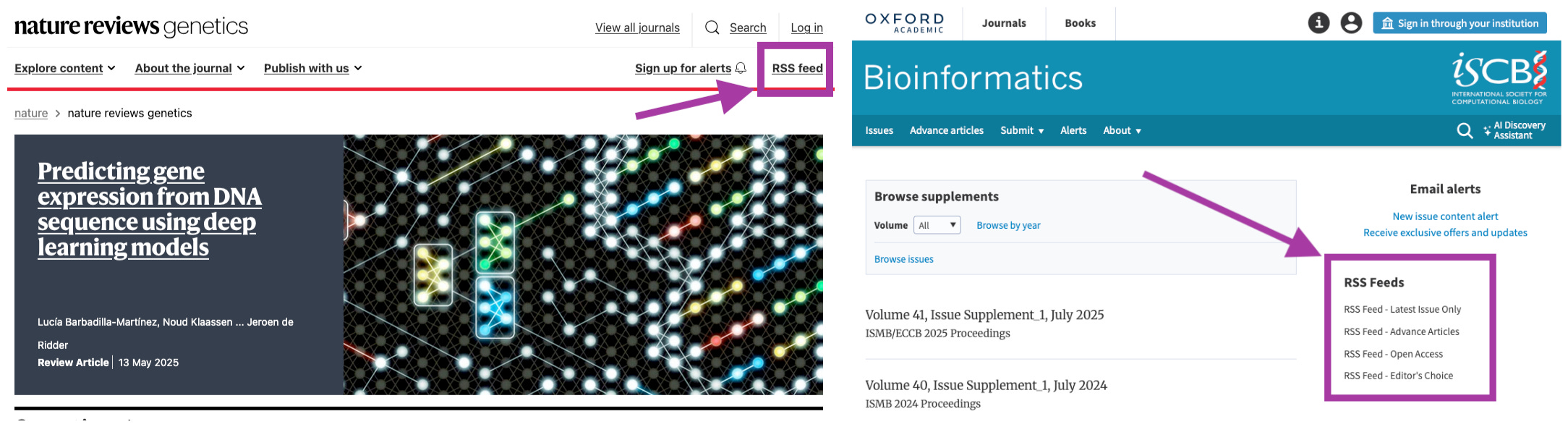
RSS isn’t dead. Long live RSS. I still use RSS to keep an eye on my favorite journals’ current and advance online issues. I’ve used Feedly (feedly.com) ever since Google Reader shut down on both the web and iOS. Here are a few of the journals I subscribe to via RSS. It might take a little hunting around each journal’s website to find the RSS feeds (examples below). Alternatively, Feedly’s built-in RSS feed search is pretty good if you just search for a particular journal title.
Finding the RSS feed from Nature Reviews Genetics and OUP Bioinformatics.
These are very domain-specific journals with limited scope, but often the most interesting papers are published in more general journals like those in the Nature portfolio (e.g. Nature Methods, Nature Communications), Cell, Science, and many others. I don’t subscribe to TOC RSS feeds for all of these and tend to rely on preprints, blogs, and keyword alerts to find relevant topics published in broad-scoped journals. Read on.
Preprints
By the time you’re reading something in the current issue of Nature Whatever that research was done at least a year ago, probably more. You’ll get the most bleeding edge research by following bioRxiv and other preprint servers.
This link to bioRxiv will take you to the alert/RSS page where you can individually subscribe to RSS feeds for particular subjects you’re interested in. I subscribe to bioinformatics, genetics, genomics, synthetic biology, and scientific communication & education.
Lately I’ve been using alphaXiv (alphaxiv.org) to find new/interesting papers and talks. I get recommended papers and webinar announcements based on my interests. Webinar recordings are all available on the alphaXiv YouTube channel.
Social media
I hesitate to make any specific recommendations here. I recommended a bunch of Twitter accounts back in 2017. Most of them aren’t active any longer, and if they are you have to wade through a cesspool of right wing propaganda and promoted AI slop to find the needles in the slopstack.
I almost exclusively use Bluesky these days even though I still cross-post to X, treating X as write-only.
You can check out who I follow on Bluesky for some inspiration. I also keep a “High SNR” list on X where I used to curate accounts that were high signal low noise, but I haven’t done any curation on this list in years.
I also follow Bluesky accounts for the same journals and preprints I mentioned above. I might scroll past a paper on my RSS feed, but maybe I’ll see it on Bluesky, or vice versa.
I usually prefer to stay away from algorithmically curated content, but as of the time I’m writing this, the Popular with Friends feed on Bluesky is useful to me. I’ve massively scaled back the number of accounts I follow, relentlessly pruning my follow list of any accounts with more than occasional snark, quote-dunking, or performative political discourse. But often those accounts I don’t follow for those reasons sometimes post gems that I’d otherwise miss. The Popular with Friends feed surfaces some of these for me, and has also been helpful for me to find new accounts and early career scientists I wouldn’t have otherwise seen.
I also use Sill (sill.social) — a service that monitors your Bluesky feeds to find the most popular links in your network. I get an email every morning showing me links that garnered attention that I probably missed.
Blogs, newsletters, and aggregators
I’m cautiously optimistic that the dwindling utility of social media is causing a resurgence in long-form blogging (I’m an advocate!). Certainly the infrastructure is making things easier — since my 2017 post we’ve gotten tools like Quarto for publishing technical blogs, and I’ve discovered many interesting blogs/newsletters through the Substack network of recommendations.
Here are a few that I subscribe to and read regularly (in alphabetical order). Most are Substack blogs you can get delivered to your email. The others I subscribe to via RSS.
Since you’re here reading about blogs and newsletters I recommend, here’s a shameless plug: Subscribe to Paired Ends to get posts like this delivered instantly to your email!
Pubmed and Google Scholar alerts
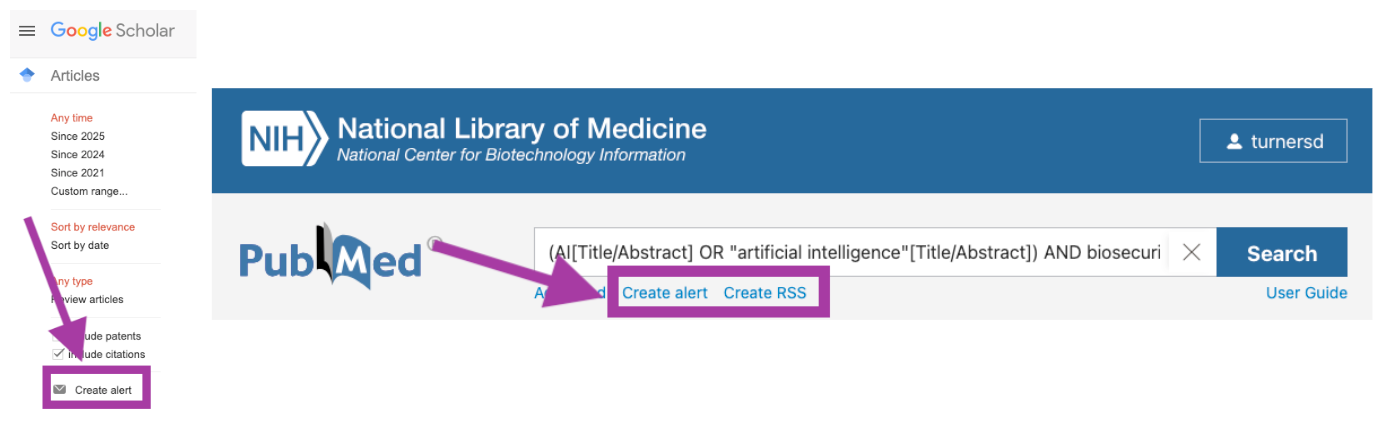
I create email alerts on both Google Scholar and Pubmed. I set things up to alert me instantly or daily for late-breaking research close to my heart, or weekly or monthly for things I want to be aware of but don’t necessarily need to see it first. Also, it’s worth learning a little about advanced searching in PubMed. For instance, you can set up alerts for particular authors, collaborations, or keywords in either the title, abstract, or full text. For example, I have this alert set up for finding something with [either “AI” OR “artificial intelligence”] AND “biosecurity” in either the title or abstract.
(AI[Title/Abstract] OR "artificial intelligence"[Title/Abstract]) AND biosecurity[Title/Abstract]
Scheduled tasks in ChatGPT
This one’s new. You can use GPT-5 to schedule tasks like a new literature/web search and email you summaries every morning or on whatever schedule you choose, and you can edit these at chatgpt.com/schedules once you set them up. Here are a few example prompts I use to set up alerts and summaries for papers/blogs/articles I wouldn’t expect to find in a particular domain-specific journal.
Here’s a prompt to set up a scheduled search/summary for papers on AI and data science education:
Search for technical papers or blog posts that present perspectives or empirical results on the impact of AI tools like ChatGPT on data science and biology/life sciences education. Prioritize items that propose concrete strategies for teaching and assessment (e.g., assignment design, grading, oral exams, lab courses). Include direct links. After providing papers and links, summarize everything in a table at the end. Only notify me if you find new or updated items since the last run.
Example result:
And here’s another I use to surface new papers and technical reports on AI and biosecurity.
Search for technical papers, blog posts, or model cards from Meta, OpenAI, DeepMind, xAI, or Anthropic that present reproducible, benchmarked evidence of the impact of AI on biosecurity, AI as a biological design tool, AI for lowering the tacit knowledge barrier, and perspectives on new research areas in AI and biosecurity. Include links and summarize in a table, and notify me if any new ones are found.
Semantic Scholar
Last year I wrote a long post mostly about a tool called Inciteful that I use to find literature related to a set of “seed” papers:
Near the bottom of this post I write a little about Semantic Scholar. You can add papers to individual libraries you create, and set up a regularly scheduled email to alert you about new papers related to those already in your library.
Here’s the relevant excerpt from that post above.
Semantic Scholar (semanticscholar.org) is a free AI-driven search and discovery tool. You start by searching for a subject or paper. Each paper has an AI-generated TLDR, with some citation information available on the side.
Once you find a paper, you can save it to your Semantic Scholar library, and you can save papers into different collections. Once you do so, you can opt in to receiving regular emails with newly published research that’s highly related to papers in one or more of your collections. This is the feature I love most about Semantic Scholar. Where Inciteful doesn’t have a login or session persistence, Semantic Scholar helps with staying on top of recently published literature relevant to literature you’ve already collected.
I’ll warn you, like with Google Scholar alerts and ChatGPT scheduled tasks, some of the papers you’ll surface here will be low-quality, maybe even in predatory journals. Still, the signal-to-noise is high enough for me to find it useful.
Since I started compiling this post a few months ago, Bluesky (which I still recommend) has become more annoying with the entry of more journalists, brands, bots, and people with strong opinions dogmatically held on AI. I hope Bluesky lasts as a useful social network for scientists, but no social media network ever has.
Everyone has a podcast now. I didn’t even get to those.
Vertical video has taken over the internet. Science will be next.
My own interests are shifting. I started my professional career in genetics and public health, spent some time in national security and then de-extinction, before coming back to UVA School of Data Science. In my research dean position I’m interested in everything from biosecurity to human health to education to missile defense to athletics to history of technology and social science. And not because I have to be — one of the most amazing parts about my new job is the privilege I have to work with the most talented, thoughtful, and driven scientists I’ve ever worked with. And as I write this we’re growing, hiring many new faculty members next semester. As the School of Data Science and the field as a whole evolve, so too will my interests.
In the meantime, subscribe here or check back in a few years for the part 4 update.