
Five things (July 2, 2026): AIxBio, NIH, QED
GeneBench-Pro, LLM agents and biological tools, the volition premium, NIH’s 235 flagged words, QED’s top 1%
It’s a holiday week here in the US but not a quiet one. I’ll be glamping at the lake tomorrow so this one’s coming a day early. June 30 was a busy day for AI in science. OpenAI posted a genomics benchmark, Anthropic shipped Claude Science and brought Fable 5 back online, and I spent a good chunk of the day test driving Claude Science myself before starting my AI Dry July.

In any case, here are the five things that interested me the most this week.
OpenAI builds a genomics benchmark
RAND asks whether LLM agents can drive biological tools
David Brooks on who thrives once intelligence gets cheap
NIH’s 235-word screen, and a list to check your abstract against
QED scores preprints and names the top 1%
1. OpenAI grades its own homework
OpenAI’s Jeremiah Li and Andrew Ho posted GeneBench-Pro on bioRxiv, an expanded version of GeneBench. OpenAI also wrote a blog post about it.
Li, J. H. & Ho, A. J. GeneBench-Pro: Evaluating Multistage Statistical Reasoning in Genomics, Quantitative Biology, and Translational Biomedicine. 2026.06.29.735386 bioRxiv Preprint at https://doi.org/10.64898/2026.06.29.735386 (2026).
It’s 129 problems across 10 domains with a genomics core. Each one hands an agent a short bit of context and a target quantity to estimate, then makes it work through a series of dependent decision points. These decision points are the kind of inferential forks where one plausible wrong turn can reshape everything that comes downstream. The point is to test whether a model can run a realistic multi-stage analysis end to end and not just answer multiple choice questions (though some multiple choice questions can be challenging!).
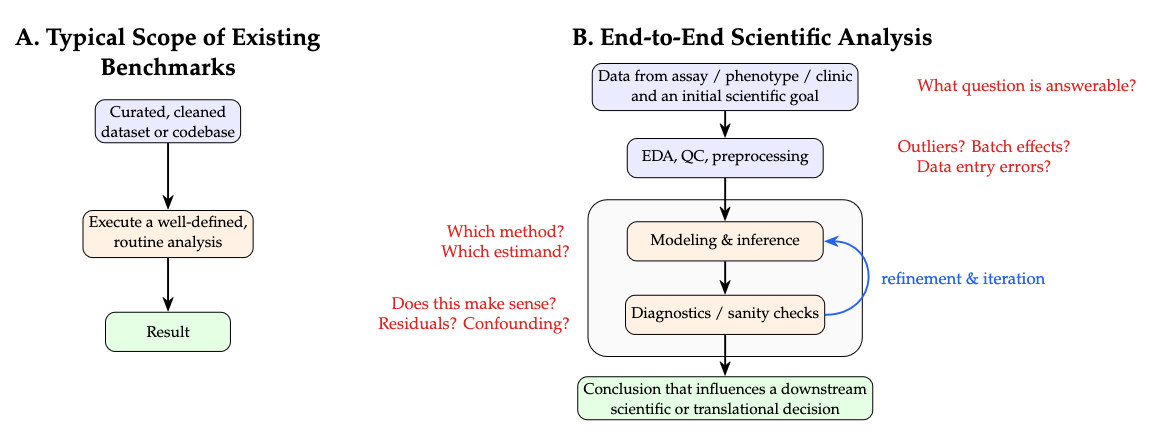
The scores: GPT-5.6 Sol Pro tops out at 31.5%, GPT-5.6 Sol at 28.7%, GPT-5.5 at 12%, and the best non-GPT model, Claude Opus 4.8, at 16%. OpenAI wrote a benchmark, ran its own models on it, and reported that they win. Worth saying plainly IMHO. In fairness, they released some problems publicly and gave many others to Artificial Analysis for independent scoring, which is more transparency than most self-graded benchmarks bother with.
There’s lot’s of buzz about GLM 5.2 lately, so I was a little surprised to see it rank so low compared to other models here.
Failure modes are interesting. The models often do most of the workflow correctly, then show what the authors call “a consistent gap between noticing and acting”: they flag a diagnostic signal but don’t carry its implication over to the decision it should change, so they pick the wrong estimator or stay on a plausible but wrong path.
That matches what I saw in my Claude Science test drive the same day. It collected the data and ran the analysis without much help, and a quick read through its code turned up several spots where it had assumed something I wouldn’t have.
The timing was crowded. This dropped alongside Claude Science and the Fable 5 redeployment. If you use Fable 5, note the cost change: it’s included for up to half your weekly usage through July 7, then it runs on metered usage credits after that.
Fable 5 will be included for up to 50% of weekly usage limits through July 7, after which it will be available via usage credits.
2. AIxBio: Picking the tool is the easy part
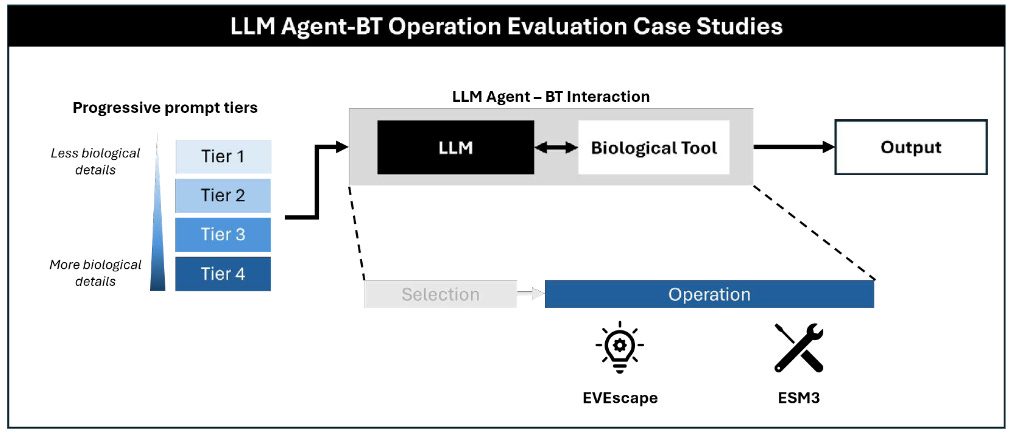
RAND’s Center on AI, Security, and Technology (CAST) tested 7 frontier LLM agents on two questions: can they pick the right computational biology tool for a task, and can they operate one (report, PDF).
Lee, J. et al. Can LLM Agents Select and Engage with Biological Tools? An Initial Biosecurity Assessment. https://www.rand.org/pubs/research_reports/RRA4741-1.html (2026).
The case studies used EVEscape, which predicts immune escape, on influenza hemagglutinin and Lassa GPC, and ESM3, a protein design model, on GFP and influenza HA.
Asked to name the right tool for a stated function, the models did well, many around 80%. Put the same question inside a realistic biological workflow and accuracy fell across the board. Operating the tools was mixed and depended on the specific protein, and when the agents failed it was usually because they mishandled data or fumbled an autonomous step, not because they lacked the knowledge. Feeding an agent more biological detail didn’t reliably help, and on the HA-targeted ESM3 task more information sometimes made things worse, which undercuts the tidy “expertise plus AI equals uplift” story.
And the closed-weight models refused a lot, especially on viral proteins and obvious dual-use requests, through either the model declining or a content filter catching it. Agents can already handle the front end of this work, that could lower the expertise barrier for a non-expert, and it deserves closer testing. This is an initial assessment on toy tasks, and they say so, so I’d strongly resist reading it as evidence that agents can build a functional biological weapon.
3. Intelligence is cheap, volition isn’t
David Brooks, writing in The Atlantic, starts with the observation that AI hasn’t handed anyone a 15-hour workweek.
The People Who Will Thrive in the AI Age: What will differentiate people is not how smart they are but their relationship to mental effort.
He cites ActivTrak data showing that when workers adopted AI their email and chat time more than doubled, their business software use rose 94%, and their focused, uninterrupted work fell 9%, plus a Berkeley Haas finding that people started pulling previously-outsourced tasks back in-house because AI made them easy.
My favorite line in the essay:
When intelligence is plentiful, volition is valuable.
He sorts people into three groups. Productive Passengers, low appetite for hard thinking, get more done and get hollowed out. Reluctant Optimizers mean to resist and get pulled in anyway. Mental Marathoners push back and use AI to widen their range rather than shrink it. Behind the hollowing-out worry he stacks a pile of studies: an MIT Media Lab result where brain connectivity dropped by half during ChatGPT-assisted tasks, a colonoscopy study where physicians’ adenoma detection fell after the AI was taken away, and a Wharton experiment where people accepted a deliberately-wrong model’s answers 80% of the time.
Some good practical advice at the end. Ask for hints instead of answers, write your own take on a blank page before you open the chat, and “ask for thinkers, not thinking,” meaning have the model summarize who has already worked on your problem so you can go read them. I started my AI Dry July this week, so I’ll report back on whether a month of added friction does anything measurable for my gamma waves.
4. A list of 235 words to avoid
Max Kozlov at Nature reports that hundreds of NIH grant applications are stuck in a screen that runs after peer review. An algorithm checks each application’s title, abstract, and summary sections against a list of disfavored terms, 235 of them as of February, including “gender,” “climate change,” “racism,” and “fossil fuel.” A hit flags the application, and the program officer is then told to renegotiate the language or drop the project.
This screen runs after two rounds of peer review and after the program officers and the institute director have already judged the work fundable. Then it enters a phase called Status 19, where NIH leaders and an HHS counselor can weigh in, with internal feedback that Nature obtained questioning whether a given study is worth funding because it looks “likely to end up in a Congressional waste report.” Most applications clear in two weeks, but a tenth of the renewals that reached this phase this fiscal year have sat for more than seven weeks, some indefinitely. NIH told Nature it keeps no banned-word list and doesn’t base funding on specific words; the internal documents suggest flagged projects simply draw far more scrutiny.
I pulled the 235 terms out of the article into a searchable page, with the CSV on GitHub, so you can run your own grant proposal against it. You can also search/page through the flagged terms below.
5. The 1%, scored
QED Science ran its QED Score, an anonymized AI metric for a manuscript’s originality and validity, across 57k bioRxiv preprints from May 2025 to April 2026 and named the top slice The 1%. Their whitepaper reports three validation studies: an AUC of 0.867 separating expert-labeled “Limited” papers from the rest on a 925-paper set, a Spearman ρ of 0.63 between a preprint’s score and the SJR of the journal it eventually landed in (scored with models whose knowledge cutoffs predated the corpus, to rule out contamination), and a blinded head-to-head where experts sided with the QED-favored paper in 75% of 60 decisive judgments.
I’ve been building my own peer-review skill in the open on the theory that most of these products are a frontier model wrapped in a good SKILL.md plus some connectors, and I’d rather that scaffolding be something the rest of us can see and fork.
Other open tabs
A few other tabs I have open that I’ll get to here soon.
LatchBio created a refusal benchmark for biosecurity risk assessment (result, paper, blog). I wrote about refusal theater here a few weeks ago.
The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
Autodata: An agentic data scientist to create high quality synthetic data
Paper mill cancer studies get double the number of citations as genuine papers
Lab-created ‘SpudCell’ marks ‘stunning’ step toward building life from scratch