
Test Driving Claude Science
Anthropic released Claude Science today. I tried it out for an AIxBio literature review and for an analysis using the IUCN Red List API with R.
Anthropic released Claude Science today, a desktop app that runs analyses on your own machine claiming that it can trace every step from raw data to finished figure. Read Anthropic’s blog post here, or this story in STAT+ if you have a subscription.
I took it for a test drive to do a literature review, and for another little project that involved data collection and analysis that I’ve been putting off for well over a year. It went off and worked on its own for a couple hours without intervention. While it didn’t one-shot everything I had in mind, it’s definitely a step change in how I’d have previously approached this little project.
What Anthropic says about Claude Science
Screenshots in this section are from Anthropic’s blog post.
I’ve watched enough “AI for science” launches turn out to be a chat window with a biology system prompt. I tried to read into the blog post to see what parts that go past that. There are a few.
Provenance. When the app makes a figure, it attaches the code that produced it, the environment it ran in, a plain-language account of what it did, and the full message history that led there. This makes it sound like you can open a plot from months ago, see exactly how it was made, then ask it to drop the gridlines or switch an axis to log scale and watch it edit its own code. I.e., docs and chat logs attached to the artifact itself. Nothing revolutionary here, but some nice cohesion that my stack currently lacks.
Reviewer agent. While an analysis runs, a separate agent checks the outputs and flags bad citations, numbers it can’t trace to a source, and figures that don’t match the code that generated them, correcting as it goes. I.e., one agent producing and another checking, aimed at the part of comp bio where mistakes are hardest to catch and most expensive to ship.
It runs where your data already lives. Looks like you can install it on your laptop, a lab Linux box, or an HPC login node, and it writes and submits jobs over SSH. The Python and R kernels persist across the session.

Claude Science is pre-configured for genomics, single-cell, proteomics, and cheminformatics, connecting to 60+ scientific databases out of the box.

Trying it out for myself
Screenshots in this section are my own.
I wanted to get a closer look at this before I start my AI Dry July. I downloaded and signed in. It’ll ask you which connectors you want to use, and which skills you want to enable.
It suggested a few things it could do for me. It suggested I let it run a literature search on AI and biosecurity, focusing on dual-use and human uplift. I also prompted it with a question of my own that would involve collecting data and doing some analysis.
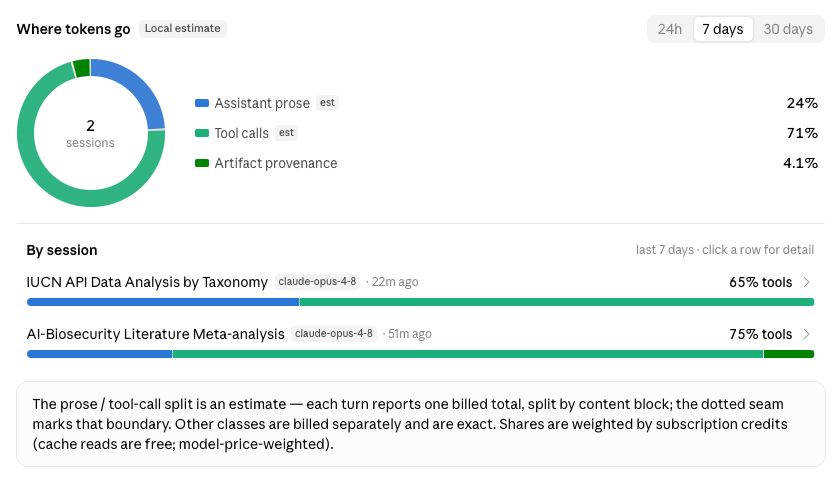
Results below, but first off, I’ll note that it started chewing through my session limits very quickly. There’s a handy update to the Usage section that shows you which sessions are using prose/tools tokens the most. I burned through my 5 hour limit with two prompts, and ate about another $50 in extra usage. Which is actually incredibly cheap relative to the time it would have taken me to do some of what it did here for me.
Literature review: AI x Biosecurity
When I logged in Claude Science suggested I let it run a literature search on AI and biosecurity, focusing on dual-use and human uplift. I said sure, and it wrote a prompt for me.
Conduct a comprehensive meta-analysis of literature at the intersection of AI and biosecurity to identify key themes, gaps, and implications for research in this emerging area.
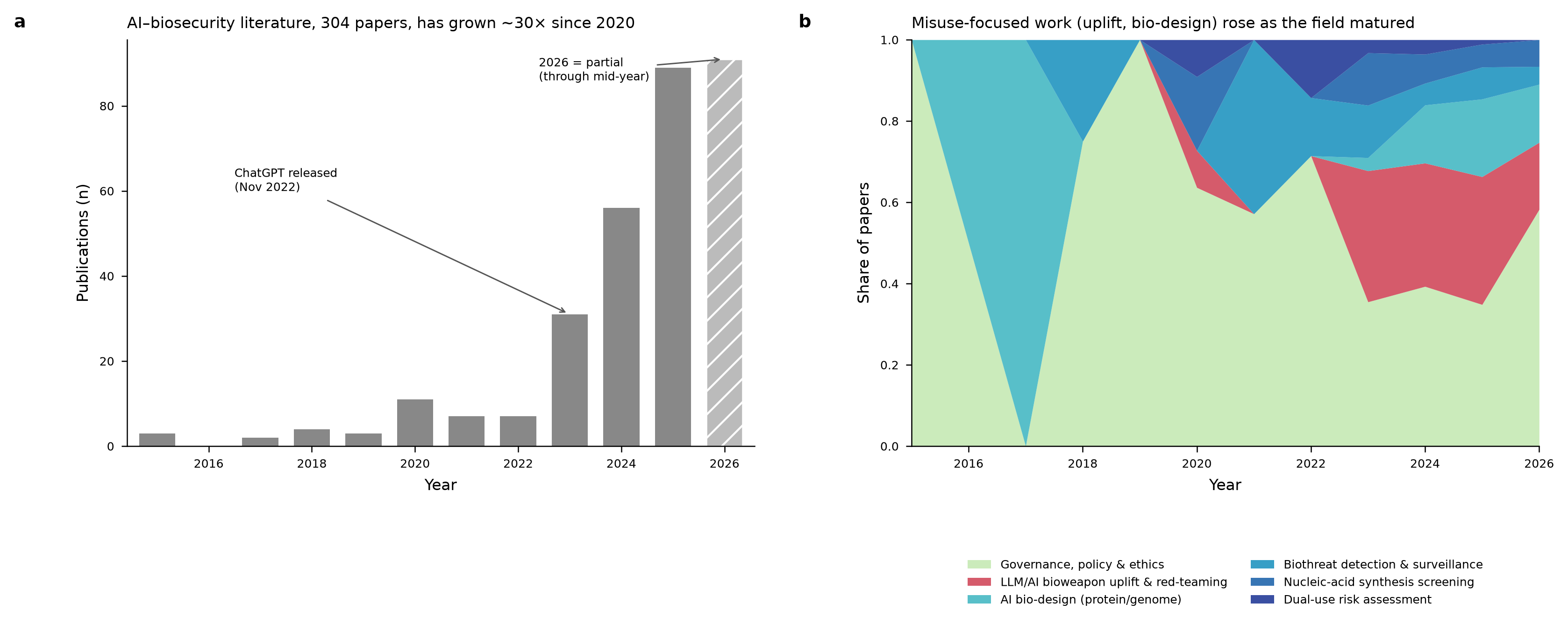
It started writing some code to search through OpenAlex, then ran that code, made some plots, and gave me back some spreadsheets of papers to look through, as well as a report (not really a meta-analysis) summarizing the state of the field, recent trends, geographical analysis, etc.
Some results and artifacts:
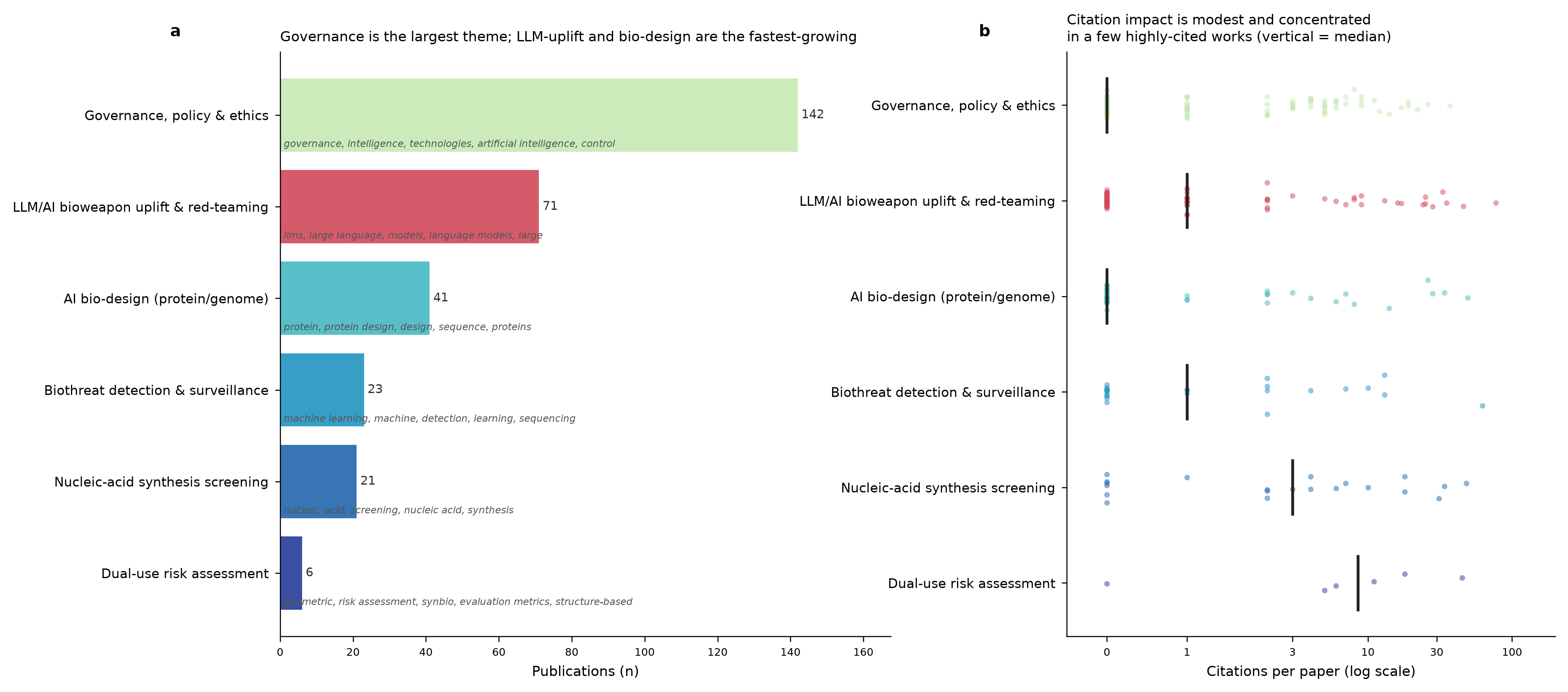
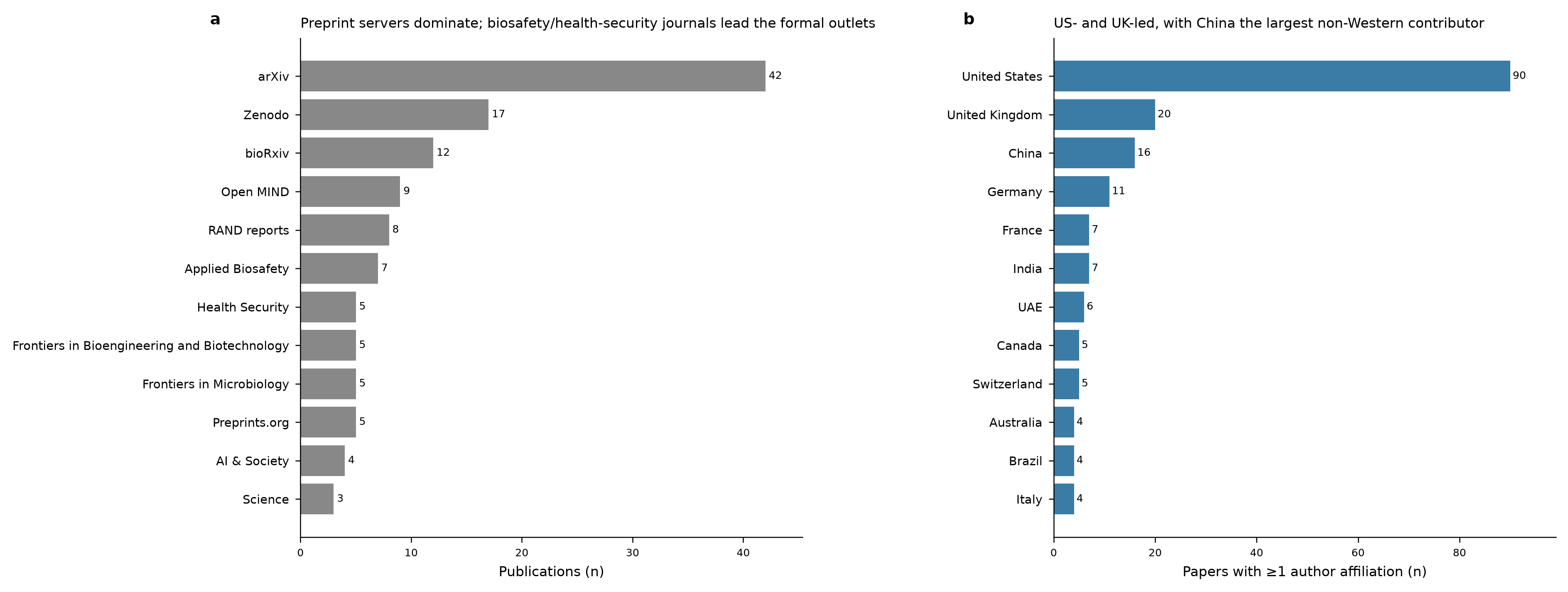
IUCN red list analysis by taxonomy
When writing this paper that was published at Nature Reviews Biodiversity, In an earlier draft, I wrote something to the effect of species on the IUCN red list can be “downgraded” to less threatened categories (e.g., critically endangered to endangered, endangered to vulnerable). An astute reviewer picked up on this and called me out on it — if I’m going to say such a thing, I’d need to back that up with some actual data or analysis.

I never had the time to do this analysis, so I just deleted the line and submitted the paper without any analysis. But I always thought it would have been interesting. Are particular taxa “downgraded” more than other taxa? How does this differ over time and geography? How might those downgradings correlate or anti-correlate with loss of genetic diversity, as we discussed in the paper?
I gave it some rough guidance:
I’d like to pull some data from the IUCN API and do some summary analysis on trends in categorization by taxonomy class, preferably using R
And set it to work.
It started poking around the IUCN API using R, inside an R notebook running in my browser that I could interact.
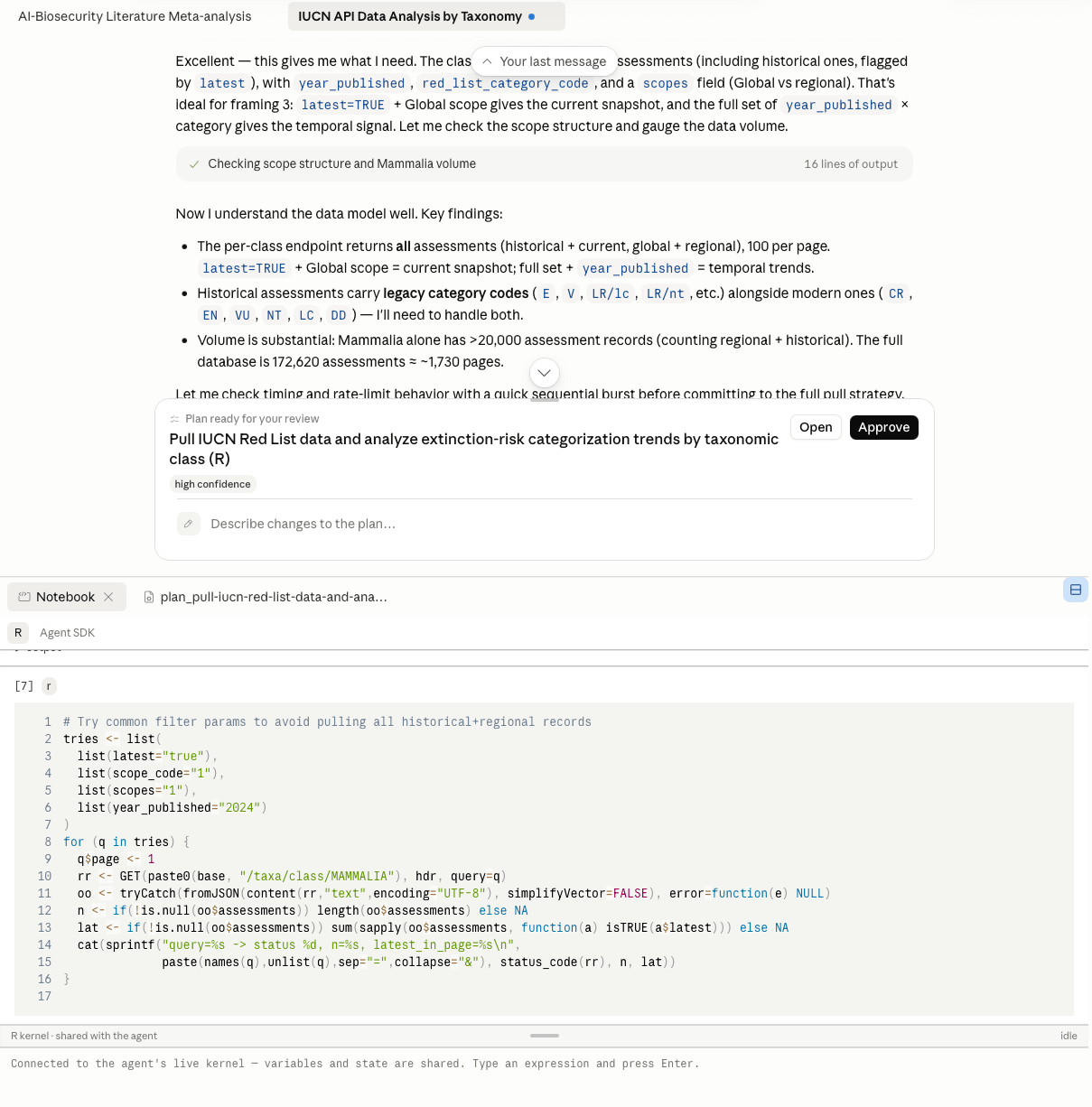
It then presented me with an analysis plan for my approval.
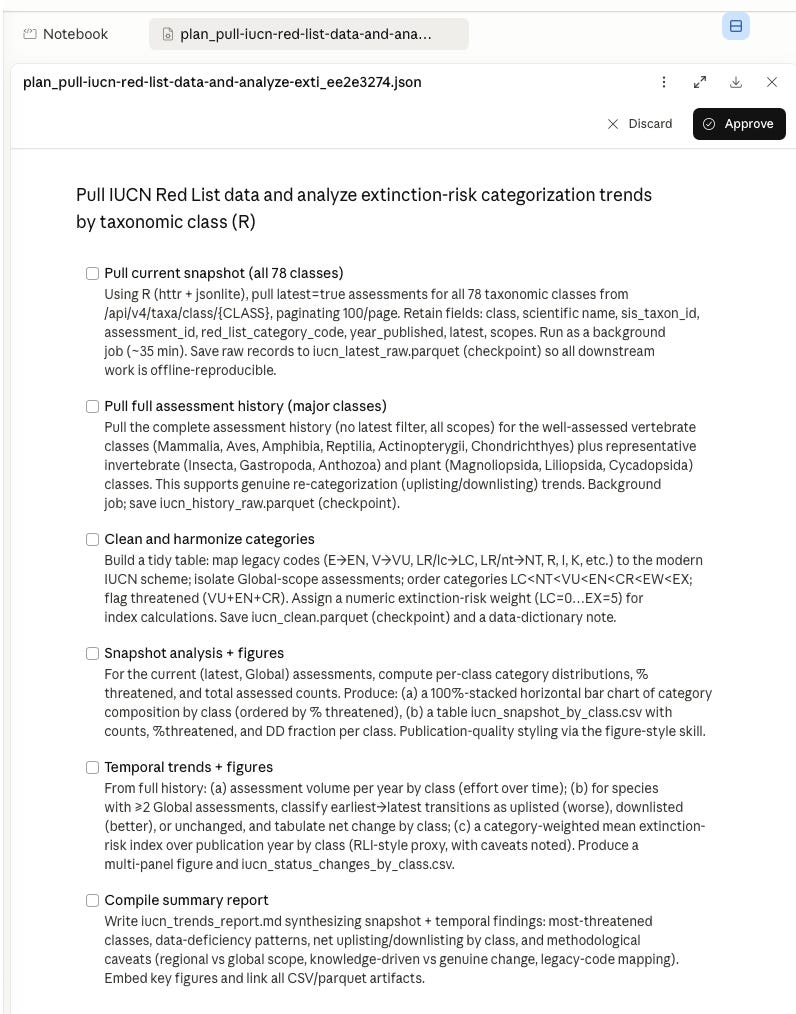
After this it continued for about 2 hours1 until it got all the data and finished the first round of the analysis, complete with a few hundred lines of R code in an ipynb that I could go in and run in the browser. I’m showing a few of the results of the analysis below, along with parts of the narrative.
Snapshot: who is most threatened now
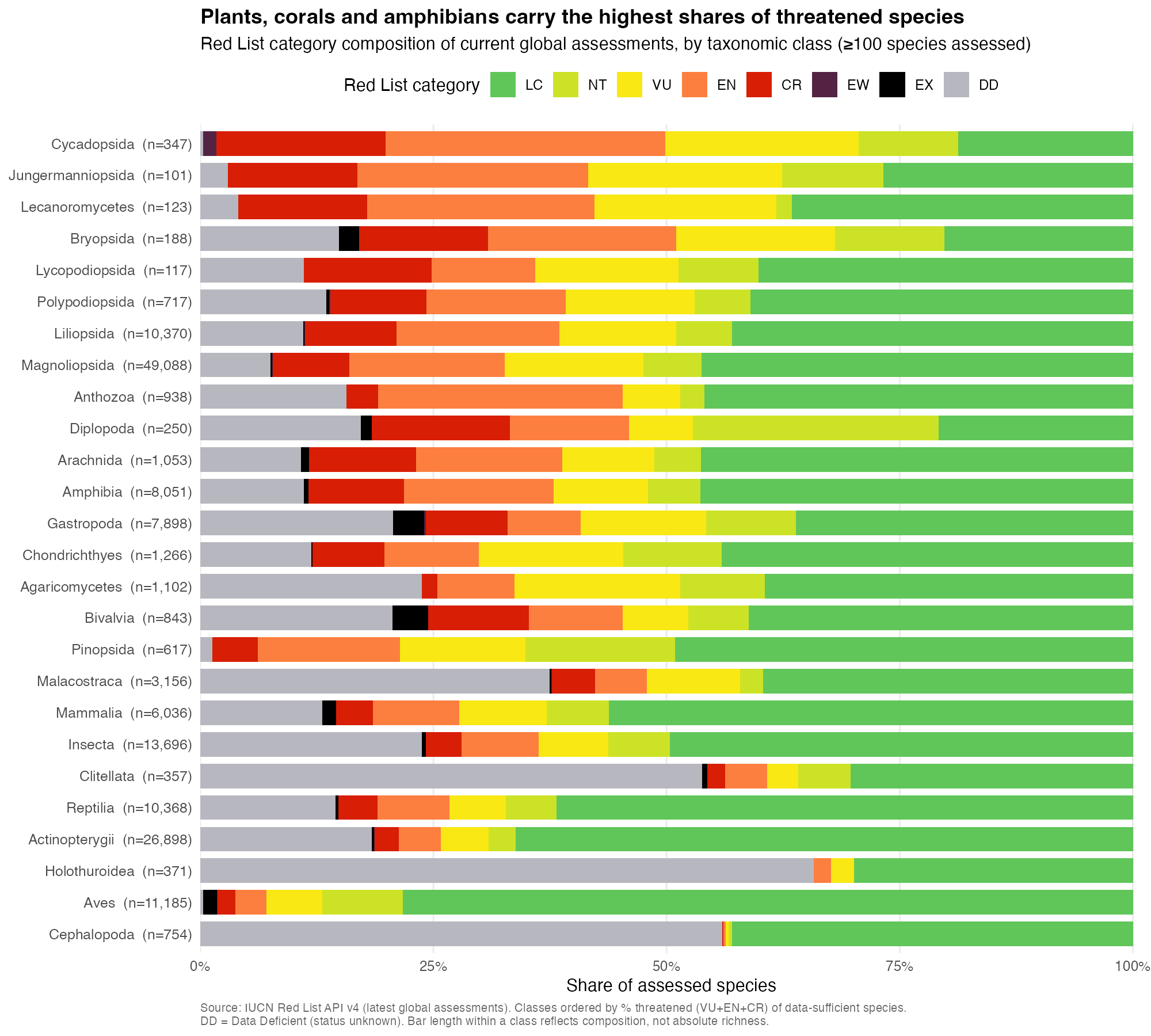
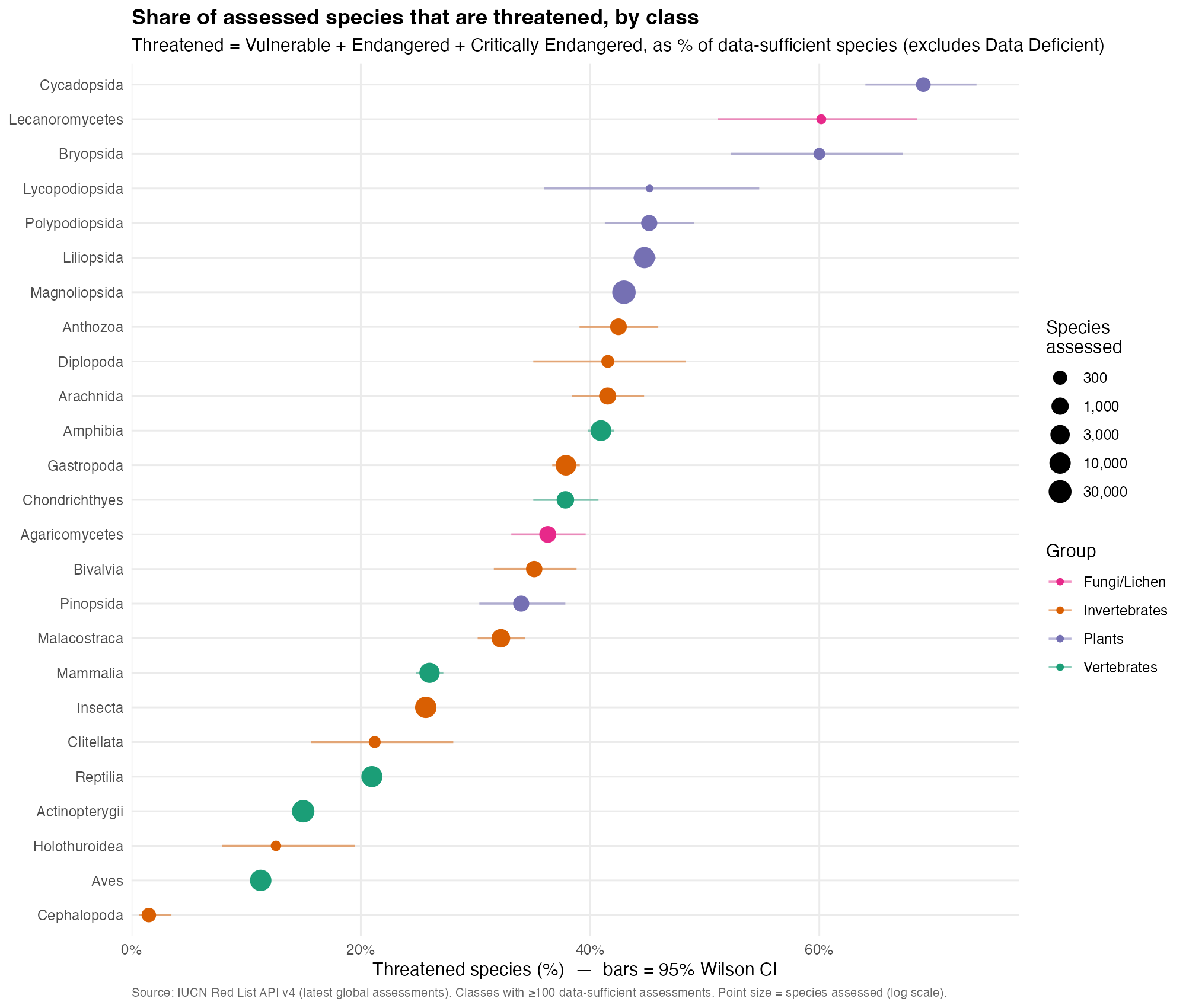
Across all data-sufficient species, 31.8% are threatened (VU+EN+CR). The threat is concentrated in plants, lichens, and several invertebrate groups, not the charismatic vertebrates:
Cycads (Cycadopsida) are the most threatened large class on Earth — 69% of assessed species. Lichens (60%), mosses (60%), ferns/clubmosses (~45%), and flowering plants (43–45%) follow.
The best-assessed vertebrates sit much lower: birds 11%, ray-finned fishes 15% — and because birds/mammals are essentially completely assessed, those figures are population-level truths, while most plant/invertebrate percentages are “of what’s been assessed so far.”
Data deficiency is its own signal: sea cucumbers (66% DD), cephalopods (56%), and earthworms (54%) are groups where status is largely unknown.
Temporal: are categories getting worse?
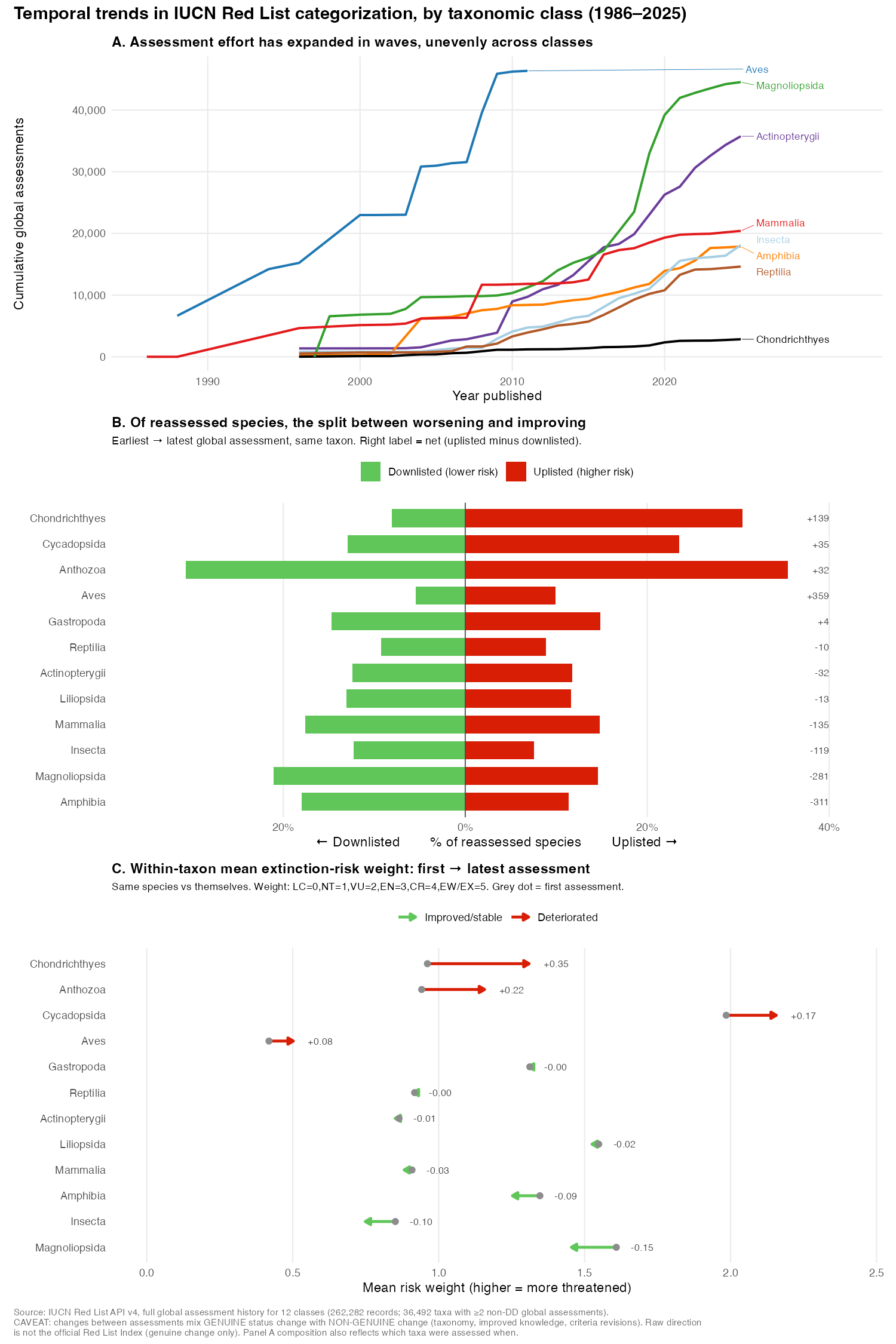
Comparing each species to itself (earliest vs. latest global assessment, 36,492 taxa):
Sharks and rays (Chondrichthyes) show the clearest deterioration — 30.5% uplisted vs. 8.1% downlisted (net +139 species), and the largest within-cohort risk increase (+0.35). Corals and cycads also show genuine net worsening.
Important caveat: several classes (amphibians, dicots, mammals) show net “improvement” in raw numbers, but this is almost certainly not real recovery — raw category changes mix genuine status change with non-genuine reclassification (taxonomic revisions, improved knowledge, criteria changes). IUCN’s official Red List Index, which isolates genuine change, shows net deterioration for the comprehensively-assessed groups. The robust genuine signal here is the sharks-and-rays decline.
What I showed above is only a few lines of the analysis and results I’ve gotten. I’m reserving the rest of the story for a paper I’d love to eventually write once I get time to come back to this to meticulously verify everything it did for me here. I also need to step in and steer the analysis a bit. Taking a quick glance through some of the code it produced I can tell it made some choices here that I probably wouldn’t have made.
What does Claude Science mean for science?
Claude Science is landing at an interesting time, just after several recent high profile AI co-scientist papers published in Nature, and with several federal funders’ signals pointing the same direction. And, interestingly, on the same day that OpenAI introduces GeneBench-Pro.
ARPA-H’s IGoR program, which we proposed to, wants an AI-driven, interoperable research system with standardized protocols and a marketplace of validated labs, cloud labs included, that execute experiments and feed results back into models, with a stated goal of producing validated knowledge much faster than we manage now. Just last week DARPA’s Biological Technology Office put out a request for information on advancing autonomous science for biological applications, asking the field where the real bottlenecks are. The request is for input, not money, but it’s clear where DARPA is headed. The agencies funding the next decade of biology are betting on autonomy.
I don’t read any of this as the scientist getting written out. I think the thing that’ll work will keep a live, fleshy, real-life person deciding which question is worth asking and whether a result that looks interesting actually is. My short test drive made that concrete. Claude Scientist automated collecting the data and running the analysis, and then in just a brief glance through the narrative and code, I caught the spots where it had assumed something I wouldn’t have.
Claude Science and other tools that will surely follow it raise the ceiling on what a single scientist can attempt. A grad student who can fold a protein and kick off a deep database/literature search before lunch is probably working on harder problems than the one who couldn’t. That’s the bet I hope we can hold funders and toolmakers to: build systems that make researchers more capable, not less necessary,2 and keep the researcher in the catbird seat where ultimate judgment and decisionmaking happens.
Noting that the majority of this time was waiting around for getting data from the IUCN API. The code it wrote put in some delays / sleeps to be nice to the API. It noted this in the thinking traces, and told me that it would take periodic snapshots in Parquet files while it continued gathering data. Note that this time was mostly waiting around, it wasn’t burning tokens for hours.
I pulled the “more capable, not less necessary” line straight out of the ARPA-H IGoR solictation, Appendix A. I love that line, and I’m stealing it from you, ARPA-H.