

Something a little different for this week’s recap. I’ve been thinking a lot lately about the practice of data science education in this era of widely available (and really good!) LLMs for code. Commentary at the top based on my own data science teaching experience, with a deep dive into a few recent papers below. Audio generated with NotebookLM.
AI in the CS / data science classroom
I was a professor of public health at the University of Virginia School of Medicine for about 8 years, where I taught various flavors of an introductory biomedical data science graduate course and workshop series, eventually turning that course material into a book (free) using Quarto. I taught these courses using the pedagogical practices I picked up while becoming a Software Carpentry instructor — lots of live coding, interspersed with hands-on exercises, with homework requiring students write and submit code as part of their assignments. I’ve seen firsthand what every experienced software developer deeply understands — how hands-on coding practice, with all its frustrations and breakthrough moments, builds deep understanding. This method of teaching is effective precisely because it embraces the productive struggle of learning. Students develop robust mental models through the cycle of attempting, failing, debugging, and finally succeeding.
— Claude has entered the chat —
I think we are well into a pivotal moment in data science and computer science education. As Large Language Models (LLMs) like ChatGPT, Claude, and GitHub Copilot demonstrate increasingly sophisticated code generation abilities, educators are facing extraordinary opportunities and profound challenges in teaching the next generation of data scientists.
The transformative potential of LLMs as learning tools can’t be understated. I recently posted about my experience using Claude to help me write code in a language I don’t write (JavaScript), for a framework I wasn’t familiar with (Chrome extensions).

In education, these AI assistants can provide instant, contextual help when students are stuck, offer clear explanations of complex code snippets, and even suggest alternative approaches to problems. They act as always available, endlessly patient teaching assistants, ready to engage in detailed discussions about programming concepts and implementation details. The ability to ask open-ended questions about code and receive thoughtful explanations represents an unprecedented resource for learners.
However, this easy access to AI-generated solutions raises important questions about the nature of learning itself. Will students develop the same depth of understanding if they can simply request working code rather than struggle through implementation challenges? When I used to teach, my grad students and workshop participants were practitioners — they were taking my classes because they needed to use R/Python/etc. in their daily work. If I were them now, I’d turn on Copilot or have Claude/ChatGPT pulled up alongside my VSCode/RStudio. Do we really expect students to turn Copilot off just for their homework, and leave it on for their daily work? How do we balance the undeniable benefits of AI assistance with the essential learning that comes from wrestling with difficult problems without a 90% correct completion suggestion? The risk is that we might produce data scientists who can leverage AI tools effectively but lack the foundational knowledge to reason about code and data from first principles.
As I try to follow the recent research on LLMs in data science education, including some of the papers below, these questions become increasingly pressing to me. The challenge before us is not whether to incorporate these powerful tools into our teaching, but how to do so in a way that enhances rather than short-circuits the learning process. The goal must be to harness LLMs’ capabilities while preserving the deep understanding that comes from genuine engagement with computational thinking and problem-solving — the productive struggle.
For another perspective and great insight into this topic, I suggest following Ethan Mollick’s newsletter, One Useful Thing. His recent essay on “Post-apocalyptic education” is a worthwhile read on this topic.

Additionally, Ethan’s more recent post, “15 Times to use AI, and 5 Not to” cautions against using AI where the struggle is the point. In the “5 times not to use AI” section, one of those times was:
When the effort is the point. In many areas, people need to struggle with a topic to succeed - writers rewrite the same page, academics revisit a theory many times. By shortcutting that struggle, no matter how frustrating, you may lose the ability to reach the vital “aha” moment.
Are you a CS or data science educator? How does this resonate with your thoughts? I’d love to chat more on Bluesky (@stephenturner.us).
Papers (and a talk): Deep dive
Improving AI in CS50: Leveraging Human Feedback for Better Learning
Paper: Liu, R., et al., "Improving AI in CS50: Leveraging Human Feedback for Better Learning" in SIGCSE Technical Symposium on Computer Science Education, 2025. DOI: 10.1145/3641554.3701945 (to appear; currently available at cs.harvard.edu/malan/…).
This one jumped out at me because I recently recommended Harvard’s CS50 course taught by David Malan in my Python for R users post. I still go back and review the OOP section from time to time. If I were to resume teaching some of the courses I once taught in biomedical data science I think I’d try to scale them using an approach like what’s described in this paper. This paper is significant because it tackles a critical challenge in AI-assisted education: how to make AI tools that actually help students learn rather than just giving them answers, and provides concrete evidence that careful fine-tuning and evaluation can create more pedagogically effective AI assistants.

TL;DR: Harvard's CS50 course developed AI tools to provide 24/7 student support but faced challenges with the AI giving overly direct answers. They created a systematic evaluation framework combining human feedback and model-based assessment to improve the AI's teaching style. Their solutions using few-shot prompting and fine-tuning showed measurable improvements in making the AI behave more like an effective teaching assistant.
Summary: The CS50 team integrated AI tools including a chatbot (CS50 Duck) and VS Code extensions to provide scalable, personalized support for their introductory computer science course. While initial feedback was positive, they identified key challenges including "instruction dilution" where AI responses became misaligned with teaching objectives despite explicit instructions. They developed a comprehensive evaluation framework combining human-graded and model-graded assessments to systematically improve the AI's responses. Through few-shot prompting and fine-tuning on carefully curated examples of effective teaching interactions, they demonstrated significant improvements in the AI's ability to guide students toward solutions rather than providing direct answers. This work provides important insights for developing pedagogically-sound AI teaching assistants that can scale while maintaining educational effectiveness.
Methodological highlights:
Developed a dual evaluation framework combining automated model-based evaluation with human-in-the-loop assessment from teaching assistants to systematically measure and improve AI responses.
Created a fine-tuning dataset of 50 carefully curated student-tutor conversations, including 7 multi-turn interactions, to train the AI to better emulate effective teaching strategies.
Implemented both single-turn and multi-turn evaluation approaches to assess AI responses, with multi-turn being more representative of real student interactions.
New tools, data, and resources:
CS50.ai - A centralized AI backend server that relays student messages to GPT-4o hosted on Azure, incorporating pedagogical guardrails.
CS50 Duck - An AI-powered chatbot providing 24/7 support through Ed discussion platform and VS Code extensions.
Evaluation platform for comparing and assessing AI responses, incorporating both automated and human evaluation components.
ChatGPT for Teaching and Learning: An Experience from Data Science Education
Paper: Zheng, Y. “ChatGPT for Teaching and Learning: An Experience from Data Science Education” in SIGCSE 2024: Proceedings of the 55th ACM Technical Symposium on Computer Science Education. https://doi.org/10.1145/3585059.3611431.
TL;DR: A practical examination of ChatGPT's use in data science education, studying how it impacts teaching effectiveness and student learning outcomes. The study gathered perspectives from students and instructors in data science courses, revealing both opportunities and challenges specific to the field.
Summary: This study evaluates ChatGPT's integration into data science education through real-world practice and user studies with graduate students. The research investigates how effectively ChatGPT assists with tasks ranging from coding explanations to concept understanding. The findings suggest ChatGPT excels in explaining programming concepts and providing detailed API explanations but faces challenges in problem-solving scenarios. The study underscores the importance of balancing AI assistance with fundamental learning, particularly noting that ChatGPT's effectiveness varies across different aspects of data science education.
Highlights:
User studies conducted with 28 students across multiple scenarios testing different aspects of ChatGPT's capabilities in data science education.
Quantitative evaluation using a 1-5 scale questionnaire measuring student perceptions across various learning tasks.
Mixed-methods approach combining student feedback with instructor observations and practical implementation tests.

Implications of ChatGPT for Data Science Education
Paper: Shen, Y. et al., “Implications of ChatGPT for Data Science Education” in SIGCSE 2024: Proceedings of the 55th ACM Technical Symposium on Computer Science Education. https://doi.org/10.1145/3626252.3630874.
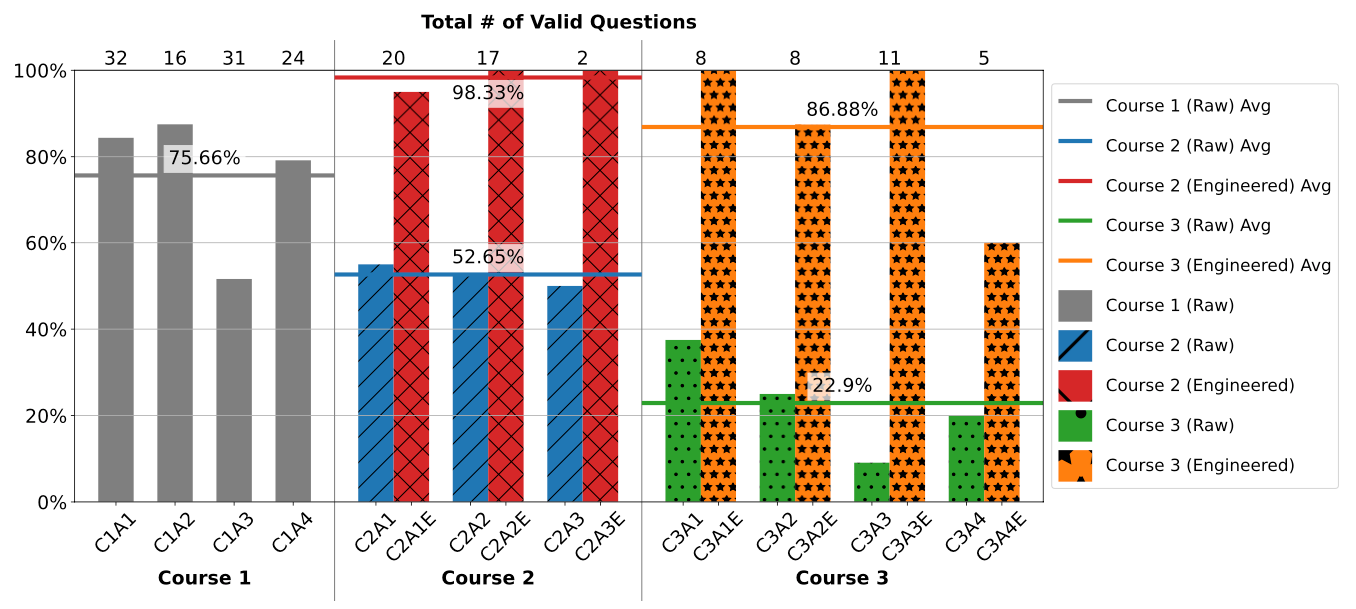
TL;DR: A systematic study evaluating ChatGPT's performance on data science assignments across different course levels. The research demonstrates how prompt engineering can significantly improve ChatGPT's effectiveness in solving complex data science problems.
Summary: The study evaluates ChatGPT's capabilities across three different levels of data science courses, from introductory to advanced. The researchers found that ChatGPT's performance varies significantly based on problem complexity and prompt quality, achieving high success rates with well-engineered prompts. The work provides practical insights into integrating ChatGPT into data science curricula while maintaining educational integrity.
Highlights:
Comparative analysis across three course levels using standardized evaluation metrics.
Development and testing of prompt engineering techniques specific to data science education.
Cross-validation of results using multiple assignment types and difficulty levels.
Evaluation framework for assessing LLM performance in data science education.
Collection of example assignments and their corresponding engineered prompts provided in supplementary materials.
What Should Data Science Education Do With Large Language Models?
Paper: Tu, X., Zou, J., Su, W., & Zhang, L. “What Should Data Science Education Do With Large Language Models?” in Harvard Data Science Review, 2024. https://doi.org/10.1162/99608f92.bff007ab.
TL;DR: A comprehensive analysis of how LLMs are reshaping data science education and the necessary adaptations in teaching methods. The paper argues for a fundamental shift in how we approach data science education in the era of LLMs, focusing on developing higher-order thinking skills.
Summary: The paper examines the transformative impact of LLMs on data science education, suggesting a paradigm shift from hands-on coding to strategic planning and project management. It emphasizes the need for curriculum adaptation to balance LLM integration while maintaining core competencies. The authors propose viewing data scientists more as product managers than software engineers, focusing on strategic planning and resource coordination rather than just technical implementation.
Highlights:
Theoretical framework development for integrating LLMs into data science education.
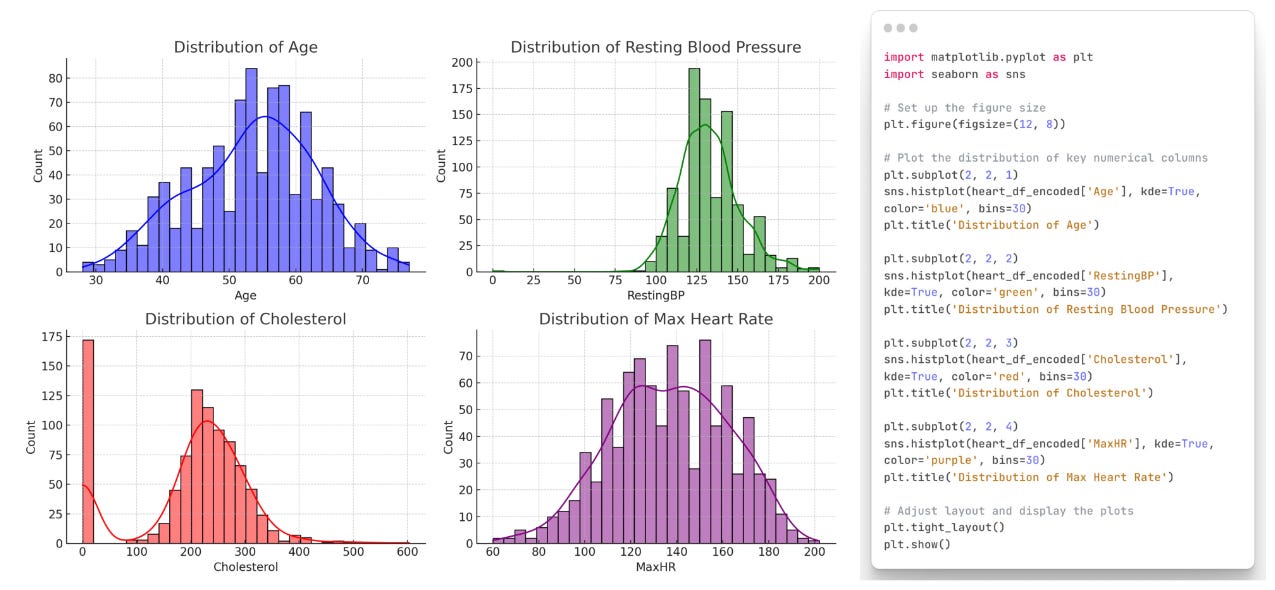
Case study analysis using heart disease dataset to demonstrate LLM capabilities.
Critical analysis of LLM limitations and educational implications.
Prompts and responses with ChatGPT provided in supplementary materials.
Talk: Teaching and learning data science in the era of AI
Andrew Gard gave a talk at the 2024 Posit conference on teaching and learning data science in the era of AI. The talk’s premise is the fact that everyone learning data science these days (1) has ready access to Al, and (2) is strongly incentivized to use it. It’s a short, ~5 minute lightning talk. It’s worth watching, and it provides a few points of advice for data science learners.
Other papers of note
Following the format I use for my normal weekly recaps, here are a few additional relevant papers that I’ve bookmarked and added to my Zotero library that I haven’t had a chance to dive into yet.
Cognitive Apprenticeship and Artificial Intelligence Coding Assistants https://www.igi-global.com/gateway/chapter/340133
It's Weird That it Knows What I Want: Usability and Interactions with Copilot for Novice Programmers https://dl.acm.org/doi/10.1145/3617367
Computing Education in the Era of Generative AI https://dl.acm.org/doi/10.1145/3624720
The Robots Are Here: Navigating the Generative AI Revolution in Computing Education https://dl.acm.org/doi/10.1145/3623762.3633499
From "Ban It Till We Understand It" to "Resistance is Futile": How University Programming Instructors Plan to Adapt as More Students Use AI Code Generation and Explanation Tools such as ChatGPT and GitHub Copilot https://dl.acm.org/doi/10.1145/3568813.3600138
Prompt Problems: A New Programming Exercise for the Generative AI Era https://dl.acm.org/doi/10.1145/3626252.3630909
Patterns of Student Help-Seeking When Using a Large Language Model-Powered Programming Assistant https://dl.acm.org/doi/10.1145/3636243.3636249
Automatic Generation of Programming Exercises and Code Explanations Using Large Language Models https://dl.acm.org/doi/10.1145/3501385.3543957
GitHub Copilot AI pair programmer: Asset or Liability https://www.sciencedirect.com/science/article/abs/pii/S0164121223001292



