
Weekly Recap (Nov 2024, part 3)
Pangenome graph construction with nf-core/pangenome, pangenome graphs, single cell multi-omics, RNA foundation models, Nextflow for B-cell receptor sequencing from nontargeted bulk RNA-seq, ...
This week’s recap highlights pangenome graph construction with nf-core/pangenome, building pangenome graphs with PGGB, benchmarking algorithms for single-cell multi-omics prediction and integration, RNA foundation models, and a Nextflow pipeline for characterizing B cell receptor repertoires from non-targeted bulk RNA-seq data.
Others that caught my attention include benchmarking generative models for antibody design, improved detection of methylation in ancient DNA, differential transcript expression with edgeR, a pipeline for processing xenograft reads from spatial transcriptomics (Xenomake), public RNA-seq datasets and human genetic diversity, a review on bioinformatics approaches to prioritizing causal genetic variants in candidate regions, quantifying constraint in the human mitochondrial genome, a review on sketching with minimizers in genomics, and analysis of outbreak genomic data using split k-mer analysis.
Deep dive
Cluster-efficient pangenome graph construction with
nf-core/pangenome
Paper: Heumos, S. et al. Cluster-efficient pangenome graph construction with nf-core/pangenome. Bioinformatics, 2024. DOI: 10.1093/bioinformatics/btae609.
Benchmarking in bioinformatics typically involves some measure of accuracy (precision, recall, F1 score, MCC, ROC, etc.), and compute requirements (CPU time, peak RAM usage, etc.). A metric I’ve been seeing more recently is the carbon footprint of a particular bioinformatics analysis. In the benchmarks performed here (detailed below), the authors calculated the CO2 equivalent (CO2e) emissions for running both nf-core/pangenome and another commonly used tool, showing that nf-core/pangenome took half the time for an analysis without increasing CO2e. It looks like the authors are using the nf-co2footprint plugin to do this.
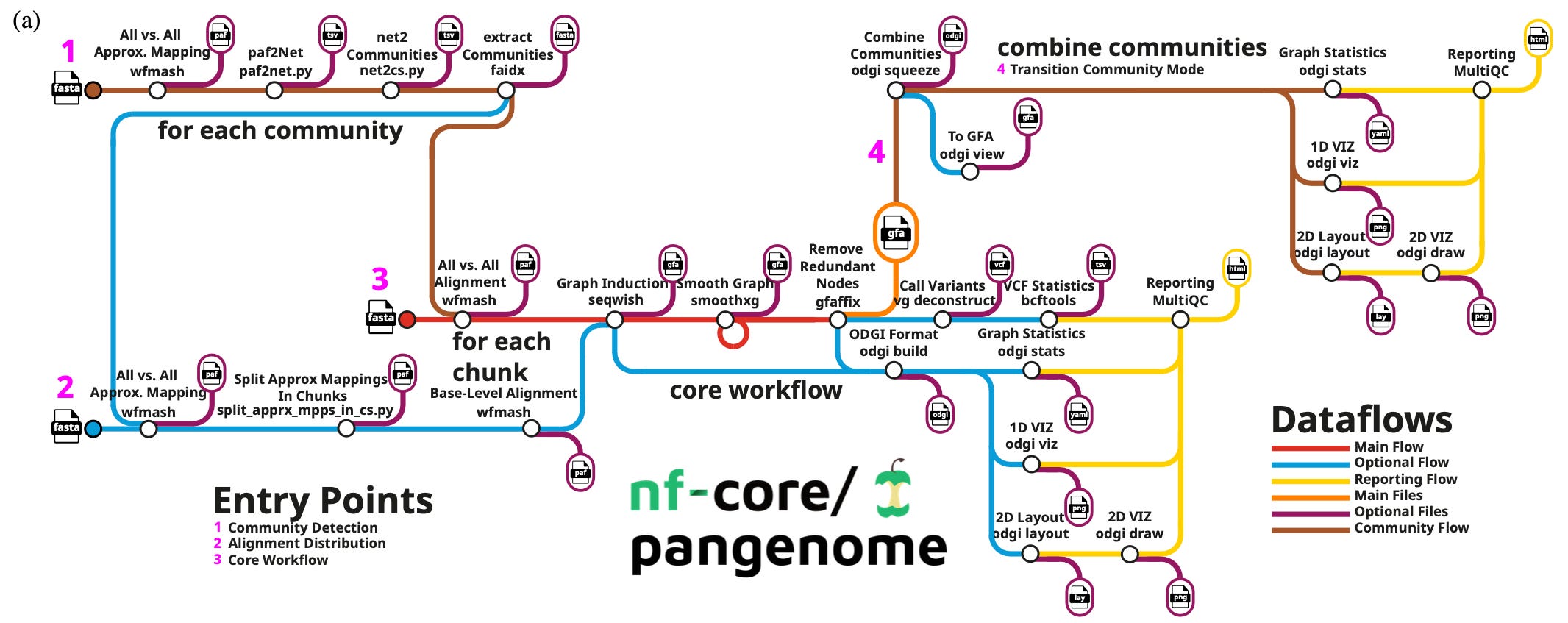
TL;DR: This paper introduces nf-core/pangenome, a Nextflow-based pipeline for constructing reference-unbiased pangenome graphs, offering improved scalability and computational efficiency compared to existing tools like the PanGenome Graph Builder (PGGB is highlighted next in this post!).
Summary: The nf-core/pangenome pipeline offers a scalable and efficient method for building pangenome graphs by distributing computations across multiple cluster nodes, overcoming the limitations of PGGB, a widely used tool in the field. Pangenome graphs model the collective genomic content across populations, reducing biases associated with traditional reference-based approaches. This work showcases the pipeline’s power by constructing a graph for 1000 chromosome 19 human haplotypes in just three days and processing over 2000 E. coli sequences in ten days—tasks that would take PGGB much longer or fail due to computational limitations. The nf-core/pangenome pipeline emphasizes portability and seamless deployment in high-performance computing (HPC) environments using biocontainers. With these features, it enables population-scale genomic analyses for various organisms, supporting biodiversity and personalized genomics research.
Methodological highlights:
Uses Nextflow for efficient workflow management and resource distribution, ensuring parallel processing and modular flexibility.
Avoids reference biases by aligning each sequence against all others with WFMASH, followed by graph induction with SEQWISH and graph simplification with SMOOTHXG.
The pipeline integrates ODGI for quality control and MultiQC for generating summary reports, ensuring comprehensive analyses.
New tools, data, and resources:
GitHub repository: https://github.com/nf-core/pangenome.
Documentation/tests: https://nf-co.re/pangenome.
Code for the paper: https://github.com/subwaystation/pangenome-paper.
Here’s a talk from last year’s Nextflow summit where Simon Heumos (lead author on this paper) talks about the workflow in detail.
Building pangenome graphs
Paper: Garrison, E. et al. Building pangenome graphs. Nature Methods, 2024. DOI: 10.1038/s41592-024-02430-3 (read free: https://rdcu.be/dXDTo)
The benchmarking paper above discusses nf-core/pangenome in contrast to PGGB, the subject of this paper. This paper was originally published in April 2023, and this updated version of the preprint contains new experimental data. The authors from this paper and the previous nf-core/pangenome paper overlap substantially.
TL;DR: This paper introduces PanGenome Graph Builder (PGGB), a reference-free tool that constructs unbiased pangenome graphs to capture both small and large-scale genetic variations. It avoids reference bias by using all-to-all alignments and provides scalable, lossless representations of genomic data.
Summary: PGGB addresses limitations in traditional genome graph tools, which often rely on a single reference genome, leading to biases and loss of complex variation. The pipeline performs unbiased, reference-free alignments of multiple genomes using the WFMASH tool, followed by graph construction with SEQWISH and graph simplification with SMOOTHXG. This modular approach captures SNPs, structural variants, and large sequence differences across multiple genomes in a unified framework. The study demonstrates PGGB’s ability to scale efficiently, building complex pangenome graphs for datasets such as human chromosome 6 and primate assemblies. PGGB is validated against existing tools, showing superior performance in accurately representing small and structural variants. Its output facilitates downstream analyses such as phylogenetics, population genetics, and comparative genomics, supporting large-scale projects like the Human Pangenome Reference Consortium (HPRC).
Methodological highlights:
Reference-free alignment: Uses WFMASH for all-to-all sequence alignment, enabling unbiased graph construction.
Graph induction and normalization: Constructs graphs with SEQWISH and smooths complex motifs with SMOOTHXG, improving downstream compatibility.
Sparsified alignment approach: Implements random sparsification to reduce computational costs while maintaining accurate genome relationships.
New tools, data, and resources:
GitHub repository: https://github.com/pangenome/pggb.
Data: Example pangenomes and validation datasets available at https://doi.org/10.5281/zenodo.7937947.
Documentation: https://pggb.readthedocs.io.

Benchmarking algorithms for single-cell multi-omics prediction and integration
Paper: Hu, Y. et al. Benchmarking algorithms for single-cell multi-omics prediction and integration. Nature Methods, 2024. DOI: 10.1038/s41592-024-02429-w. (Read free: https://rdcu.be/dW01n).
The idea behind integration of single cell data is to combine multiple types of single cell omics data (genomics, transcriptomics, epigenomics, etc) to get a more complete understanding of individual cell states. An example: maybe you use Seurat to map scRNA-seq data onto something like scATAC-seq obtained from the same tissue to identify nearest neighbor cells for a given cell across data types, and use the mapping to predict protein abundance or chromatin accessibility. This paper benchmarks many different integration approaches, making the distinction between vertical integration (different modalities), horizontal integration (batch correction across datasets), and mosaic integration (multi-omic datasets sharing one type of omics data).
TL;DR: This study benchmarks 14 prediction algorithms and 18 integration algorithms for single-cell multi-omics, highlighting top performers such as totalVI, scArches, LS_Lab, and UINMF. It also provides a framework for selecting optimal algorithms based on specific prediction and integration tasks.
Summary: Single-cell multi-omics technologies enable simultaneous profiling of RNA expression, protein abundance, and chromatin accessibility. This paper evaluates 14 algorithms that predict protein abundance or chromatin accessibility from scRNA-seq data and 18 algorithms for multi-omics integration. totalVI and scArches consistently excel in protein abundance prediction, while LS_Lab demonstrates superior performance in predicting chromatin accessibility. For multi-omics integration tasks, Seurat and MOJITOO lead in vertical integration, while UINMF and totalVI excel in horizontal and mosaic integration scenarios, respectively. The study uses 47 datasets across diverse tissues and experimental setups to provide robust recommendations for algorithm selection in different single-cell workflows.
Methodological highlights:
Two evaluation scenarios: Intra-dataset (same dataset split into train/test) and inter-dataset (train on one dataset, test on another).
Six performance metrics: cell‒cell Pearson correlation coefficient (PCC), protein-protein PCC, cell-cell correlation matrix distance (CMD), protein-protein CMD, AUROC and RMSE.
Evaluation framework: Compares prediction and integration algorithms across single-cell RNA + protein and RNA + chromatin datasets.
Top-performing tools: no single algorithm consistently outperformed the others in every metric and dataset. Generally, performance was better for:
totalVI and scArches for protein abundance prediction.
LS_Lab for chromatin accessibility prediction.
Seurat and MOJITOO for merging RNA expression with protein abundance.
UINMF for integrating batches of scRNA+scATAC data.
New tools, data, and resources:
Benchmarking pipeline: Available on GitHub at https://github.com/QuKunLab/MultiomeBenchmarking.
Datasets: 47 multi-omics datasets (CITE-seq, REAP-seq, SNARE-seq, 10x Multiome) were used to benchmark algorithm performance. Links to relevant resources provided in the Data availability section.

Orthrus: Towards Evolutionary and Functional RNA Foundation Models
Paper: Fradkin, P. et al. Orthrus: Towards Evolutionary and Functional RNA Foundation Models. bioRxiv 2024. DOI: doi.org/10.1101/2024.10.10.617658.
I discovered this from the Bits in Bio newsletter (which I highly recommend subscribing to). There are plenty of protein and DNA language models around, but this paper describes a new RNA foundation model that can help predict mRNA properties important for therapy and mRNA vaccine development.
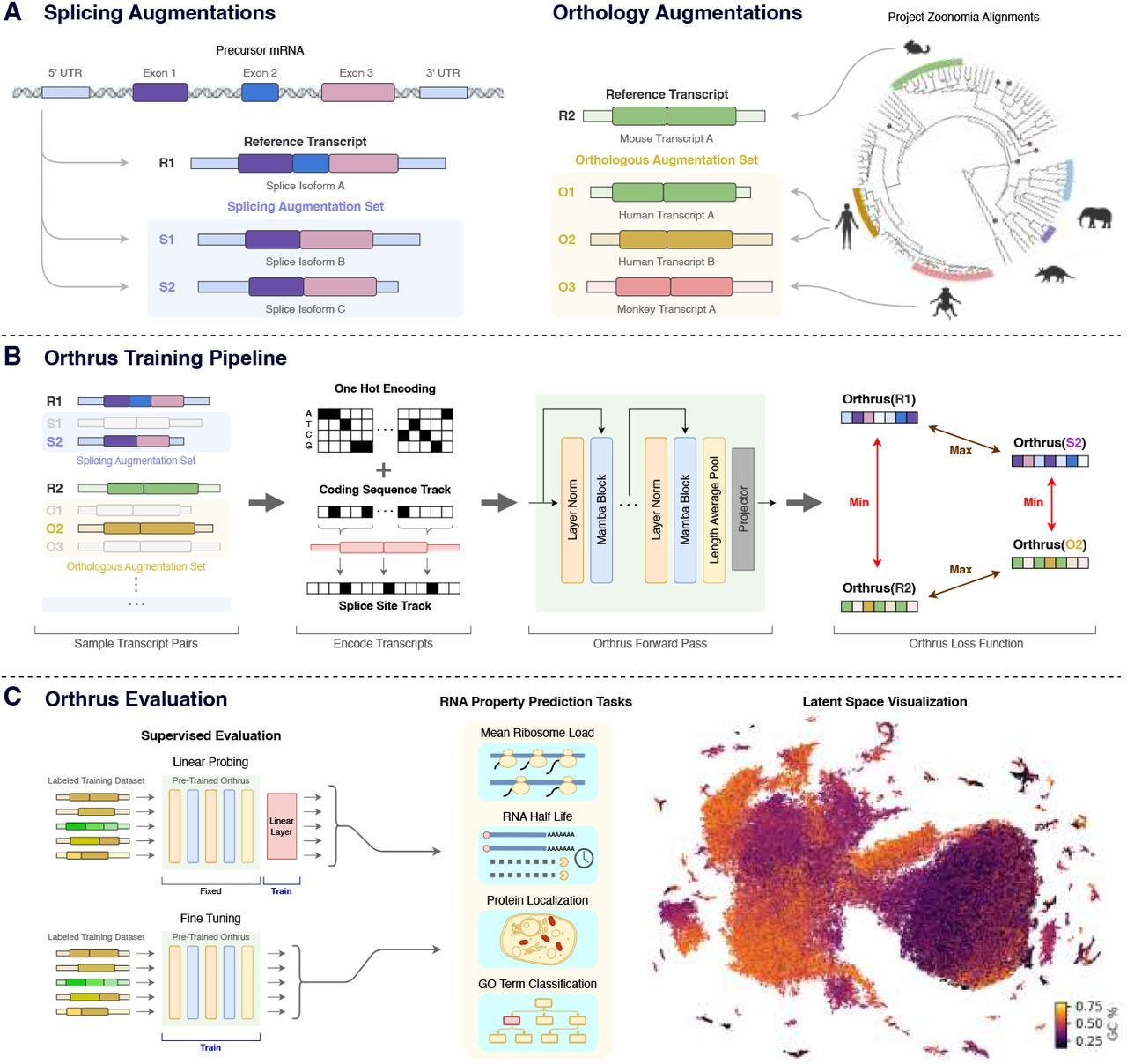
TL;DR: Orthrus is a new RNA foundation model using contrastive learning, leveraging biological augmentations like splice isoforms and orthologous sequences to predict RNA properties like half-life and protein localization, outperforming existing models in low-data regimes. The code is available at https://github.com/bowang-lab/Orthrus.
Summary: Orthrus introduces a novel approach to RNA property prediction by utilizing contrastive learning based on biological principles. It clusters RNA sequences with functional and evolutionary similarities, using data from 10 species for alternative splicing and over 400 mammalian species for orthology through the Zoonomia project. This strategy enables Orthrus to outperform other RNA foundation models, especially in low-data settings, where it requires minimal fine-tuning to achieve state-of-the-art predictions. Orthrus was evaluated on multiple tasks, including RNA half-life and protein localization, and outperformed supervised models in these areas. The model's ability to generalize well in such scenarios makes it an important tool for predicting RNA functions and understanding alternative splicing’s role in cellular processes.
bcRflow: a Nextflow pipeline for characterizing B cell receptor repertoires from non-targeted transcriptomic data
Paper: Schlegel, B. T. et al. bcRflow: a Nextflow pipeline for characterizing B cell receptor repertoires from non-targeted transcriptomic data. NAR Genomics and Bioinformatics, 2024. DOI: https://doi.org/10.1093/nargab/lqae137.
Targeted B cell sequencing (bulk or single cell) gives you in-depth profiling of the B cell receptor repertoire. The method described here is used for BCR profiling from nontargeted bulk RNA-seq data.
TL;DR: bcRflow is a Nextflow pipeline designed to analyze B cell receptor (BCR) repertoires from non-targeted transcriptomic data. It supports bulk and single-cell RNA-seq data and integrates tools for alignment, assembly, and downstream analysis.
Summary: bcRflow is a versatile, scalable Nextflow pipeline for profiling B cell receptor repertoires using bulk or single-cell RNA-seq data. It automates the extraction of immunoglobulin (Ig) sequences and their downstream analysis, which typically requires targeted immune sequencing. By leveraging the MiXCR algorithm for BCR assembly and germline sequence imputation, bcRflow identifies unique clonotypes and characterizes V(D)J recombination patterns, somatic hypermutation rates, class-switch recombination, and repertoire diversity. The pipeline is demonstrated on RNA-seq data from COVID-19 patients, revealing disease-associated shifts in BCR repertoires. bcRflow facilitates immune repertoire studies in diverse biological and clinical contexts, including infectious diseases and vaccine responses, without incurring the costs of targeted sequencing approaches.
Methodological highlights:
MiXCR-based alignment: Uses MiXCR for V(D)J gene segment alignment and BCR assembly, supporting both bulk and single-cell RNA-seq data.
Germline sequence imputation: Imputes germline sequences for assessing somatic hypermutation and immune repertoire diversity.
Modular Nextflow design: Offers high scalability, portability, and flexibility across various computational environments, including HPC clusters and cloud-based resources.
New tools, data, and resources:
Source code: https://github.com/Bioinformatics-Core-at-Childrens/bcRflow.
Docker: https://hub.docker.com/r/bioinformaticscoreatchildrens/bcrflow (
docker pull bioinformaticscoreatchildrens/bcrflow).Data availability: RNA-seq data used in this study is from GSE206263 (Differential chromatin accessibility in peripheral blood mononuclear cells underlies COVID-19 disease severity prior to seroconversion [bulkRNA-Seq]).

Other papers of note
Benchmarking Generative Models for Antibody Design https://www.biorxiv.org/content/10.1101/2024.10.07.617023v2
Improved detection of methylation in ancient DNA https://genomebiology.biomedcentral.com/articles/10.1186/s13059-024-03405-5
Faster and more accurate assessment of differential transcript expression with Gibbs sampling and edgeR v4 https://www.biorxiv.org/content/10.1101/2024.06.25.600555v2
Xenomake: A pipeline for processing and sorting xenograft reads from spatial transcriptomic experiments https://academic.oup.com/bioinformatics/advance-article/doi/10.1093/bioinformatics/btae608/7821183
Public RNA-seq data are not representative of global human diversity https://www.biorxiv.org/content/10.1101/2024.10.11.617967v2
(Review) A bioinformatics toolbox to prioritize causal genetic variants in candidate regions https://www.cell.com/trends/genetics/fulltext/S0168-9525(24)00215-4
Quantifying constraint in the human mitochondrial genome https://www.nature.com/articles/s41586-024-08048-x (free: https://rdcu.be/dXhc2)
(Review) When less is more: sketching with minimizers in genomics https://genomebiology.biomedcentral.com/articles/10.1186/s13059-024-03414-4
Seamless, rapid, and accurate analyses of outbreak genomic data using split k-mer analysis https://genome.cshlp.org/content/early/2024/10/10/gr.279449.124.short