
Six Things: June 18, 2026
Cal Newport on doom trolling, SecureBio's benchmark dashboard, RAND on biodesign audit trails, the anti-scaling law in drug development, local models growing up, and minibwa retiring bwa-mem
It’s a holiday for us here in the US tomorrow, hence the newsletter coming a day early. Six this week instead of five as a lot landed at once.
Cal Newport tells the AI labs to cut the doom trolling
SecureBio puts its AI biology scores on one dashboard
RAND’s pitch for a cryptographic paper trail on AI-designed biology
The anti-scaling law and AI’s crowding problem in drug discovery
Local models are finally good enough for real work
Heng Li’s minibwa replaces BWA-MEM
1. Cal Newport wants the doom trolling to stop
I have read Cal Newport for years, going back to Deep Work, which I recommend to anyone who says they can’t find time to think. So I came to his new NYT op-ed already sympathetic: Dear A.I. Companies: The Doom Trolling Needs to Stop. His target is what he calls doom trolling: labs cataloging the catastrophes their models might cause while insisting they are powerless to stop building them. He points at Anthropic’s “When AI builds itself” report and at Sam Altman’s posting images of the Death Star before announcing GPT-5.
Cal’s argument: either the labs believe the risk is real, in which case the only defensible move is to stop and lobby everyone else to stop, or they do not, in which case the doom talk is marketing disguised as conscience.
I liked his analogy:
Imagine if the Ford Motor Company put out a report saying that it feared its popular F-150 trucks might soon start bursting into flames, but that there was nothing the company could do about it because automotive technology was too inevitable and important to slow down. You’re probably struggling to picture this scenario because no reasonable consumer product company would ever act like this.
No consumer-products company talks this way, and he thinks AI should not get a pass for it. (He also swings at the Fable and Mythos export-control mess, reading the administration’s move as calling Anthropic’s bluff. More on that below.)
I part ways a bit. Treating a frontier model like an F-150 assumes we already agree on what the product is for and how it fails, which is the thing still in dispute. I write more about this in the biosecurity tag here.
2. SecureBio puts its AI biology scores on one dashboard
SecureBio launched a public dashboard collecting its model evaluations on biosecurity-relevant tasks, from the Virology Capabilities Test to newer agentic benchmarks like ABC-Bench. It spans 9 companies and more than a dozen metrics across three years, rolled into a “Bio Capabilities Index” built on the same method as Epoch’s capabilities index. TLDR: frontier models now clear human-expert baselines on these tests and keep climbing.
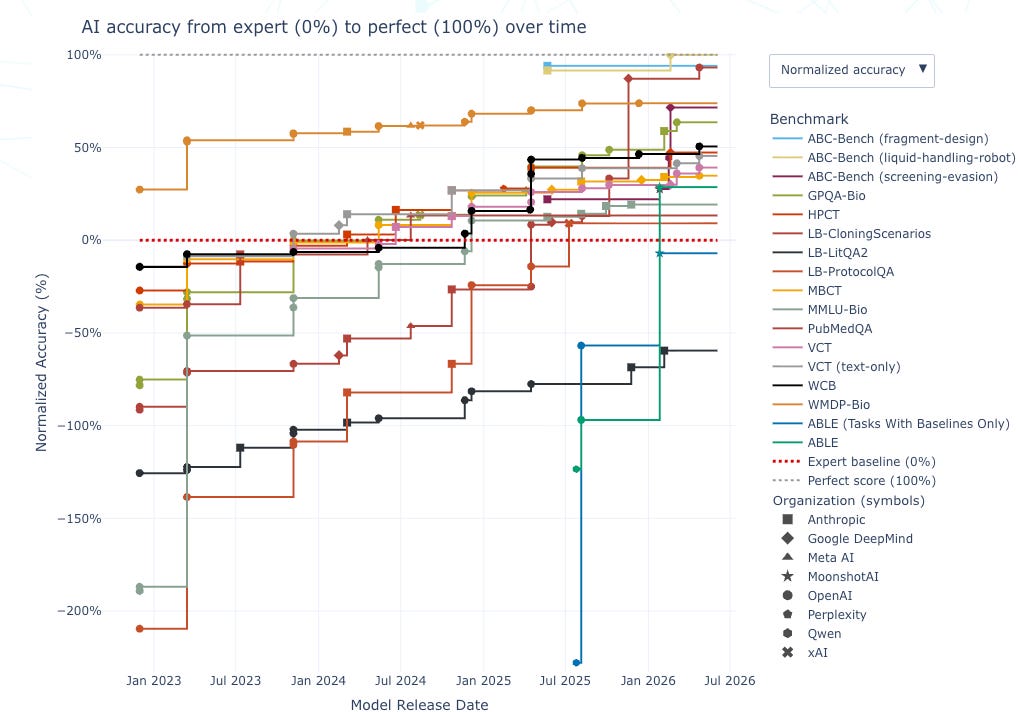
3. RAND wants a cryptographic paper trail for AI-designed biology
A new RAND CAST report, Verifiable Audit Trails for AI-Enabled Biological Design Tools (Berke, Kilian, Griffin, Atanda, Vazquez) proposes a cross-tool, tamper-evident audit trail for AI-enabled biological design tools: hardware-bound cryptographic signing, hash chaining, and append-only transparency logs so a synthesis provider or regulator can verify how a sequence was produced. The building blocks are mature in adjacent fields, and the authors argue that the technical side is the easy part.
The report is admitting the real obstacles are not technical. Nobody is set up to govern shared infrastructure, the burden falls unevenly across the research community, and institutions lack the capacity to review audit records even if they had them.

4. The anti-scaling law, and why AI might crowd drug development
Liang Chang Liang Chang’s essay was one of the the bests thing I read this week: The Anti-Scaling Law in Biology, and Why AI Could Make Crowding Worse Before Making Drug Development Better.
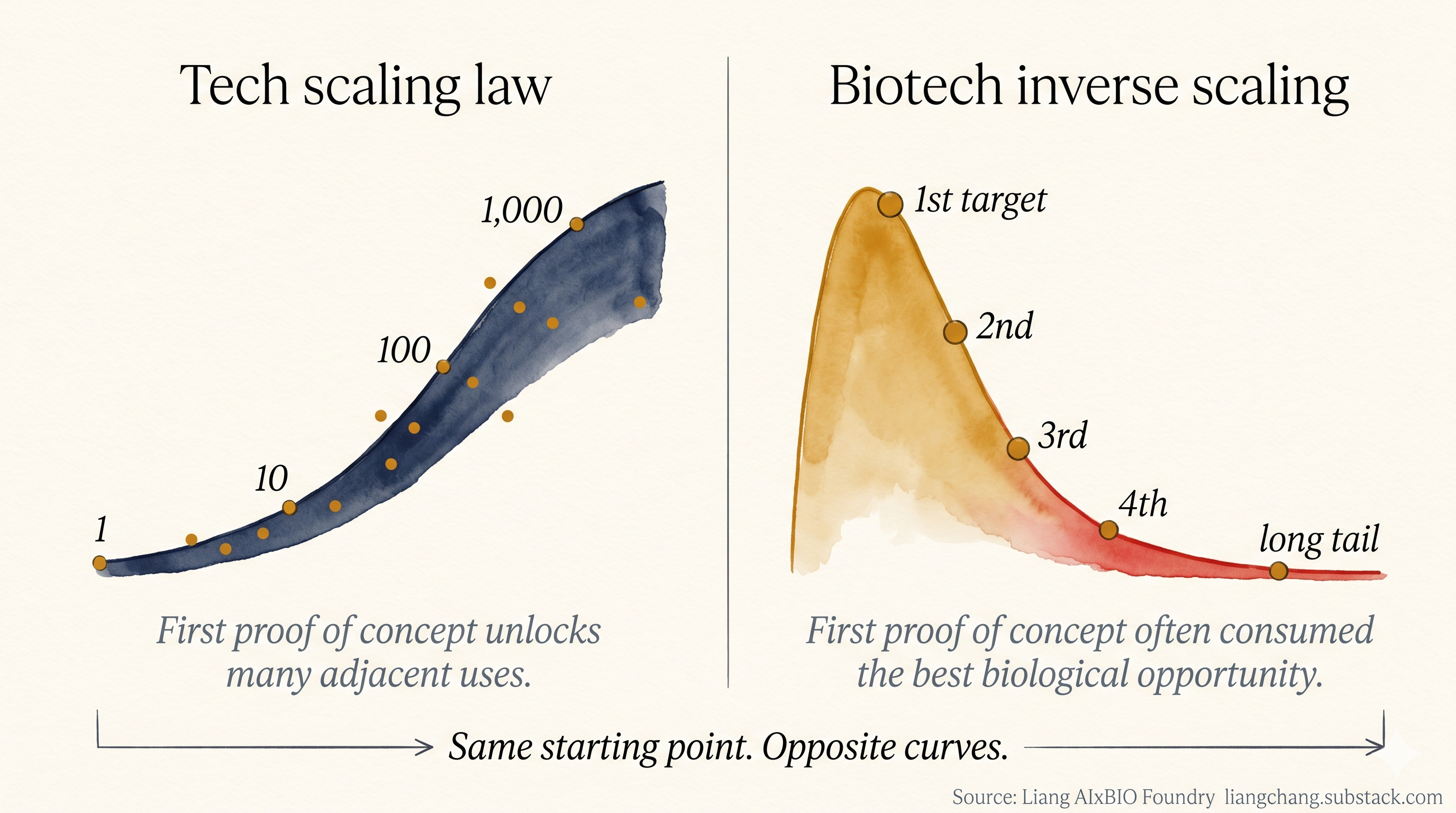
He starts from two real wins: Revolution Medicines’ pan-RAS inhibitor daraxonrasib, which moved median overall survival in treated metastatic pancreatic cancer from 6.7 to 13.2 months (HR 0.40), and Lilly’s VERVE-102 base editor, which dropped PCSK9 by up to 88% and LDL by up to 62% from a single infusion. Then he pushes back on the tech reflex that says the next hundred are queued up behind them.
His claim is an anti-scaling law. In software, proving one case lets you copy it a hundred times. In biology the first proof of concept usually consumes the single best target, because you never picked it at random, and the second is harder than the first.
AI does not democratize originality. It democratizes access to the same obvious ideas.
AI raises the floor on execution (binder design, optimization, trial ops) without moving the ceiling on the step that decides whether a drug works, which is choosing the right target for the right disease. The odds a drug entering trials reaches approval sat near 10% in 2014 and about 8% by 2020, straight through the genomics and ML era. His fear is that cheaper engineering plus training-data gravity funnels everyone onto the same validated targets, so you get 300-plus CD19 programs instead of new biology.
5. Local models grew up
Vicki Boykis recently keynoted our Applied Machine Learning Conference here in Charlottesville. I loved her talk. You can watch it here.
In her most recent blog post, Running local models is good now, she makes the case that local models crossed a line in the last few months. On a 2022 M2 Mac with 64GB, she is now doing agentic coding locally with Gemma 4 at roughly 75% of frontier speed and accuracy, refactoring a notebook into modules and writing tests, all inside a Docker sandbox. Her test for whether a model is good enough is whether she still double-checks it against an API model, and she does that a lot less now.
The HN thread is a useful counterweight to the enthusiasm.
I don’t know about good, I use a lot of local models and they’re still pretty painful to run locally
You have dense models (qwen 27b, gemma 31b) who are pretty smart, but pretty slow
You have MoE models (gemma 26b, qwen 35b, north mini code 30b) who are pretty fast, but make a lot of mistakes
You need a lot of memory to run these well, quantization makes tool calling weaker, so most run at 4 bit quants and are wondering why it kinda sucks and that’s because you’ve essentially lobotomized the model (I recommend unsloth quants, i recommend 6bit for MoEs and 5bit for dense)
So you need a lot of compute to make the pre-fill fast, you need bandwidth to make the decode fast, you need a lot of memory to hold everything - lot of ifs
On top of that, your laptop becomes a loud hot churning machine, it’s uncomfortable to work with.
So are they good? not really. Do they work? yes
One commenter daily-drives Qwen3.6-27B and prefers it to the frontier models for his workflow precisely because he wants the model to type while he does the thinking, though another warns you should not generalize from Sonnet to a lab’s actual flagship. The recurring objections are cost (”some of us have a budget”) and reliability: small context windows, and local models slipping into hallucinated tool-call JSON, which is where agentic loops break. Vicki is describing a real shift for personalized, low-recency dev work, with the production bar still a step out.
6. minibwa retires BWA-MEM
Heng Li and Nils Homer released minibwa, and Li is direct about what it is: the full replacement for BWA-MEM.
Read the preprint. Instead of another drop-in clone that preserves identical output, minibwa makes breaking changes, splicing BWA-MEM’s variable-length seeding onto minimap2’s chaining and SIMD alignment, with ropebwt3’s SMEM search and aggressive memory prefetching. The result is about 4x BWA-MEM and over 2x BWA-MEM2 at comparable accuracy, under 20GB RAM, with native long-read and directional bisulfite support that BWA-MEM never had.
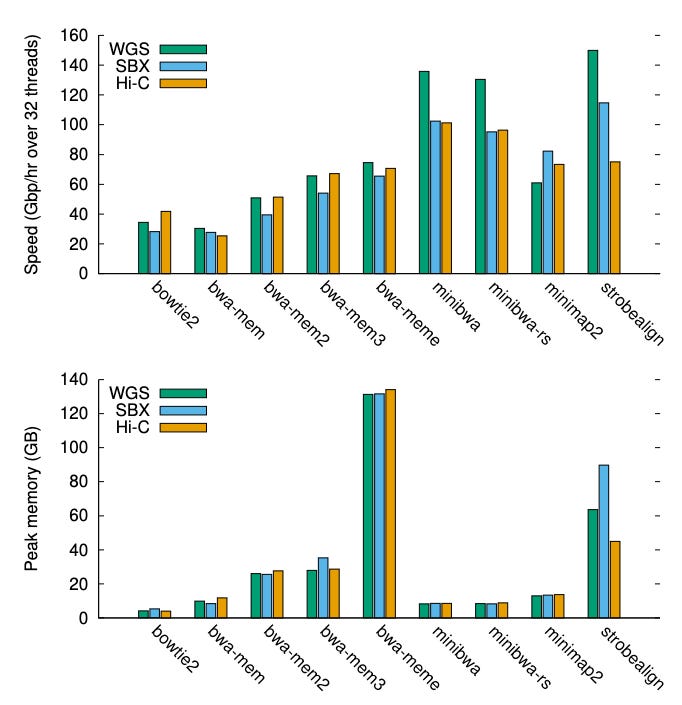
On accuracy, the comparison is closer than the speed numbers suggest. On simulated short reads BWA-MEM is slightly more accurate, and the difference comes entirely from centromeric and acrocentric regions where minibwa deliberately stops trying, since you cannot place those reads correctly anyway.
One footnote I enjoyed: the Rust rewrite, minibwa-rs, was mostly written by coding agents, which tells you something about where bioinformatics tooling is heading.

In other news…
The Fable 5 and Mythos 5 shutdown: the Commerce Department issued an export-control directive citing national security, and Anthropic pulled both models for every customer to comply. Rounding up a few articles on the topic.
Anthropic’s own statement frames it as a misunderstanding over a narrow, non-universal jailbreak (essentially asking the model to “fix this code”), and notes access to all other models is unaffected.
The HN discussion of that statement runs the predictable split over whether this is a safety call or a political one.
Katie Moussouris at Luta Security argues the export controls harm US cyber defense, since the flagged behavior is the same find-fix-test loop defenders run every day, and points to the freefable.org open letter.
Transformer’s Shakeel Hashim reads it as an AI licensing regime arriving through the back door, arbitrary and post-hoc, built on export law never designed for this.
Axios reports the shutdown came down to personality clashes and a communication breakdown with the administration, set off by Amazon’s Andy Jassy calling Treasury Secretary Bessent.
The Atlantic argues the episode is how America loses the AI race.
The Washington Post covers how Anthropic lost the White House’s trust, and then its flagship product.
The NYT’s opinion page calls it the start of a new kind of conflict.
The Superintelligence newsletter asks when a model becomes too powerful to stay public.
And lastly, the ACM AI Letters Vol. 1 No. 2 (June 2026) is now available online.1 I want to read all of the articles in the new issue.
Balancing Comfort and Growth: A Dual-Mode Theory of Human–AI Development
Autonomy or Guidance: What Users Want from AI versus Human Advisors
Identifying, Evaluating, and Mitigating Risks of AI Thought Partnerships
Rethinking Scientific Practice in the Age of Artificial Intelligence
The Harder Charge: Teaching Technical AI Literacy across Majors
AILET is a relatively new journal. From their own description: ACM AI Letters (AILET) is envisioned to become the premier rapid-publication venue for impactful, concise, and timely communications in AI. Bridging a crucial gap between traditional conferences and journals, ACM AI Letters will feature short peer-reviewed contributions that accelerate knowledge dissemination across academia and industry. This unique publication prioritizes theoretical breakthroughs, algorithmic innovation, practical real-world applications, and critical societal implications, including ethics, policy, and responsible AI. It also introduces a distinctive space for rigorously reviewed opinion pieces and policy briefs, promoting swift engagement with contemporary issues shaping the AI landscape.