
OpenScholar Synthesizes Scientific Literature and Reduces Hallucitations
An open-source small AI model from Allen Institute beats previous-generation frontier models in literature review and synthesis, and reduces hallucinated citations.
I originally wrote this for the AI Exchange @ UVA Substack newsletter on May 5, 2026. Even if you’re not at UVA I highly recommend subscribing. Ryan Wright and Varun Korisapati are publishing some really interesting stuff over there.

A recent Nature paper from UW and Allen AI introduces OpenScholar, a retrieval-augmented language model that outperforms GPT-4o1 on scientific literature tasks despite being a fraction of its size.
Asai, et al. (2026). Synthesizing scientific literature with retrieval-augmented language models. Nature. https://doi.org/10.1038/s41586-025-10072-4
OpenScholar addresses a problem with using LLMs for research: citation hallucination.2 When asked to cite recent literature across fields like computer science and biomedicine, GPT-4o3 fabricates citations 78-90% of the time. The references look plausible, but the papers simply don’t exist.
What the paper showed
OpenScholar tries to ground responses in a data store of 45 million open-access papers with 236 million passage embeddings. Instead of generating citations from parametric memory, it retrieves relevant passages, synthesizes them, and iteratively refines its output through a self-feedback loop. The model drafts a response, critiques it, retrieves additional context if gaps are identified, and revises. This cycle continues until the output meets quality thresholds for factuality and citation accuracy.
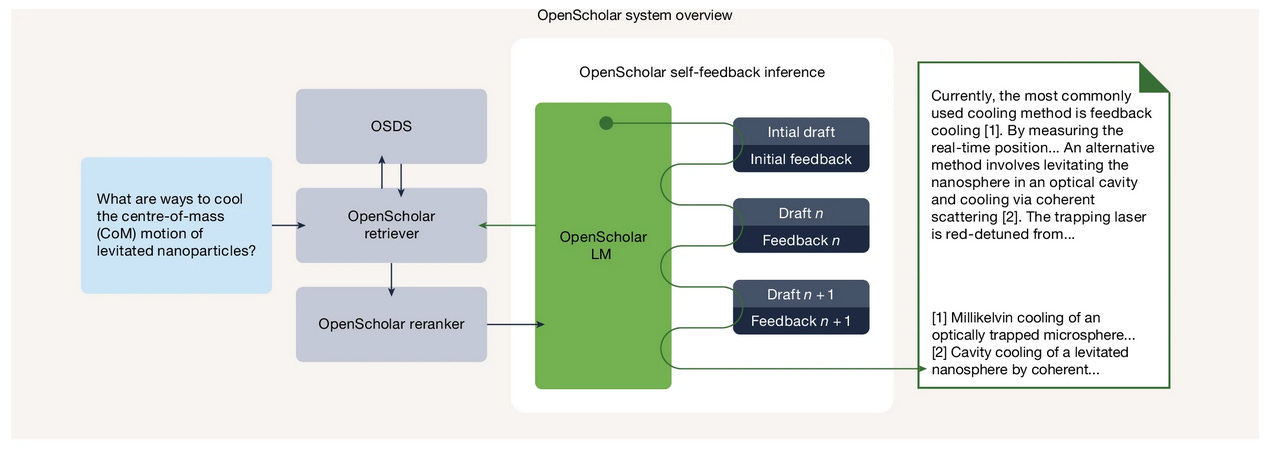
On ScholarQABench (a new benchmark the team developed with nearly 3,000 expert-written queries), OpenScholar-8B outperformed GPT-4o by 6.1% in correctness and beat PaperQA2 by 5.5%.
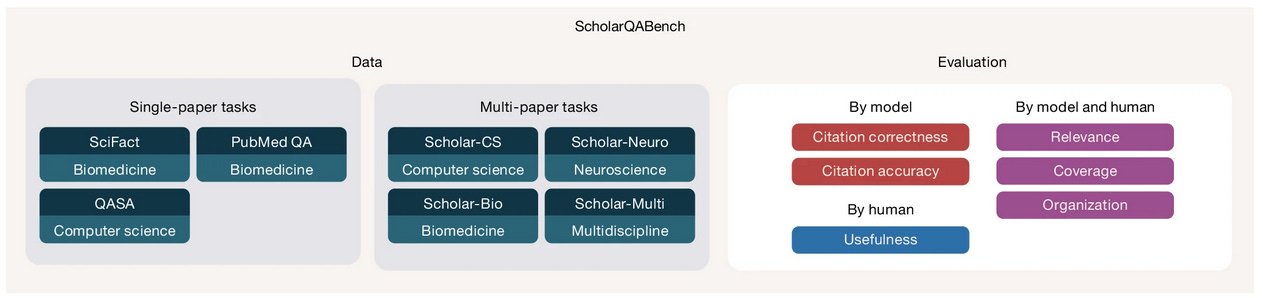
When the team ran human evaluations with 16 PhD-level experts across computer science, physics, and biomedicine, experts preferred OpenScholar’s responses over human-written answers 51% of the time (70% when using GPT-4o as the backbone).

Open source
Everything is released: models, training data, data store, retrieval indices, benchmark, and a public demo. The demo has already attracted 30,000+ users generating 90,000 queries.
Training data: https://huggingface.co/datasets/OpenSciLM/OS_Train_Data
Benchmarking: https://github.com/AkariAsai/ScholarQABench/tree/main/data
Queries: https://huggingface.co/datasets/allenai/openscilm_queries
OpenScholar code: https://github.com/AkariAsai/OpenScholar
Code to run the evals: https://github.com/AkariAsai/ScholarQABench
Public demo: https://openscholar.allen.ai
Limitations
A notable limitation: the benchmarking predates current frontier models, and only compares OpenScholar to now-deprecated ancient models. Ethan Mollick recently remarked on a different paper to this effect:

That is: Benchmarks age fast. If a weaker model is close, a better model will often clear the bar later, and we learn little from the gap.
GPT-5.5 with extended thinking, Claude Opus 4.7, and commercial tools with deep research capabilities (like Gemini Deep Research or Perplexity Pro’s updated pipelines) remain untested. Whether domain-specialized RAG maintains its edge against these newer systems is an open question.
See also
See also my previous post on Consensus, and wiring up your own Zotero library to it, to be able to ask and answer questions about your own literature collection, find gaps, and fill those gaps in.

Come to my workshop
On June 17 2026 at noon I’ll be teaching a workshop for UVA’s AI Research Initiative AI upskilling series: Smarter Literature Reviews with AI-Powered Tools. You can register for the workshop here. Grab your spot now!
Yes, GPT-4o. A deprecated model that no one uses anymore.
I don’t know if someone else has used the word previously, but I’m calling these “hallucitations.”
Personal anecdata: the frontier models at the actual frontier (GPT-5.4, Opus 4.7, as of this writing), especially with extended thinking enabled, have far fewer hallucitations than GPT-4o or other last-generated deprecated models. See the end of the post.
their search did a nice job answering my question: https://openscilm.allen.ai/query/dd7791f6-a63f-4cd4-b155-068040dd34ab