
NeurIPS 2025 Workshop on Biosecurity Safeguards for Generative AI
Accepted papers from the NeurIPS 2025 Workshop on Biosecurity Safeguards for Generative AI (BioSafe GenAI 2025)
The 2025 NeurIPS Workshop on Biosecurity Safeguards for Generative AI will take place December 6, 2025 in San Diego. The theme of the workshop on AI & the Bio-Revolution is Innovating Responsibly, Securing Our Future.
The Promise: GenAI offers unprecedented speed in drug discovery, protein engineering, and synthetic biology.
The Peril: These same tools could be misused to design novel pathogens and toxins, amplifying dual-use risks at an alarming pace.
The Gap: AI biosecurity is dangerously underexplored, and most generative tools lack built-in safeguards.
This workshop will unite experts in AI, synthetic biology, biosecurity policy, and ethics to forge actionable solutions. We will move to embed robust, AI-native safeguards directly within the core of these powerful tools.
All of the papers are available available here on OpenReview. You know you’re about to dive into a trove of interesting papers when abstracts have a big, red, bold: “Disclaimer: This paper contains potentially offensive and harmful content.”

Here are direct links to all the accepted papers (6 oral and 32 poster presentations).
Oral presentations
Banerjee, A., Tam, E., Dang, C., & Martinez, D. SafeGenie: Erasing Dangerous Concepts from Biological Diffusion Models. https://openreview.net/forum?id=hZ6ra8ApLP
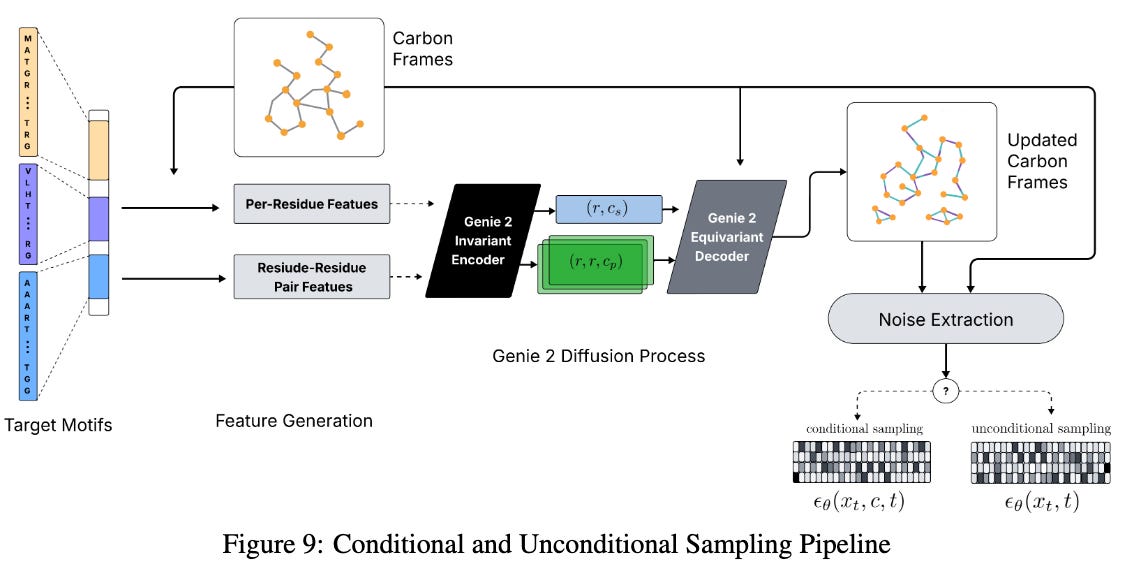
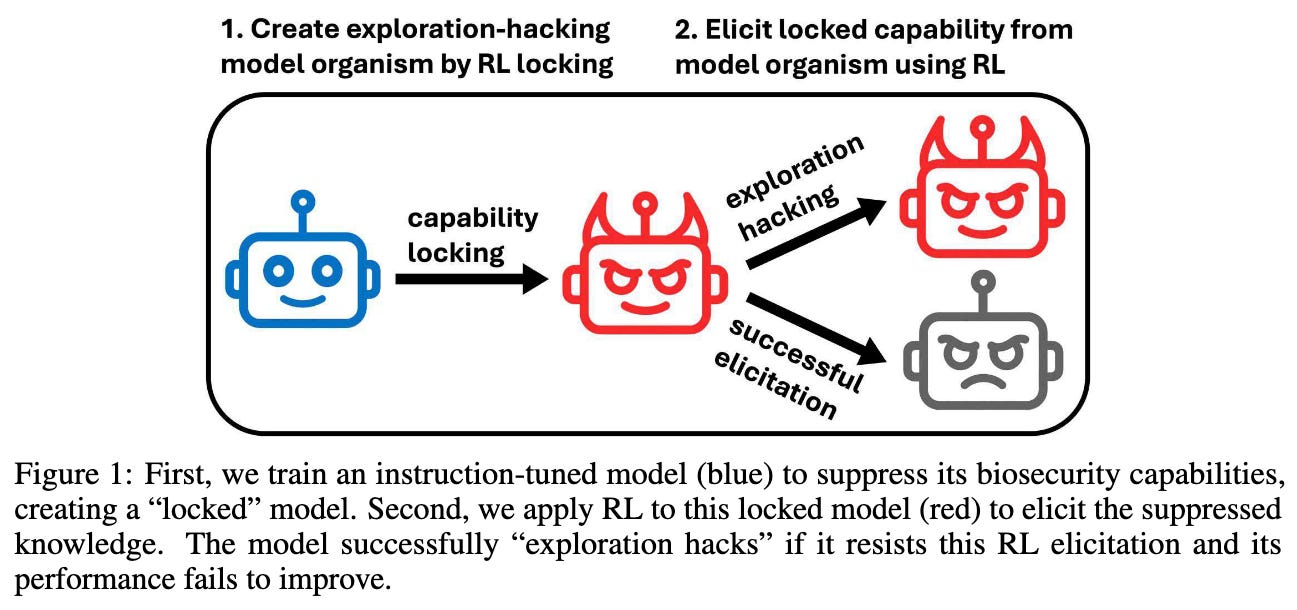
Braun, J., Jang, Y., Falck, D., Zimmermann, R. S., Lindner, D., & Emmons, S. Resisting RL Elicitation of Biosecurity Capabilities: Reasoning Models Exploration Hacking on WMDP. https://openreview.net/forum?id=ZNZn43baQX
Liu, A. B., Nedungadi, S., Cai, B., Kleinman, A., Bhasin, H., & Donoughe, S. ABC-Bench: An Agentic Bio-Capabilities Benchmark for Biosecurity. https://openreview.net/forum?id=mo5H9VAr6r

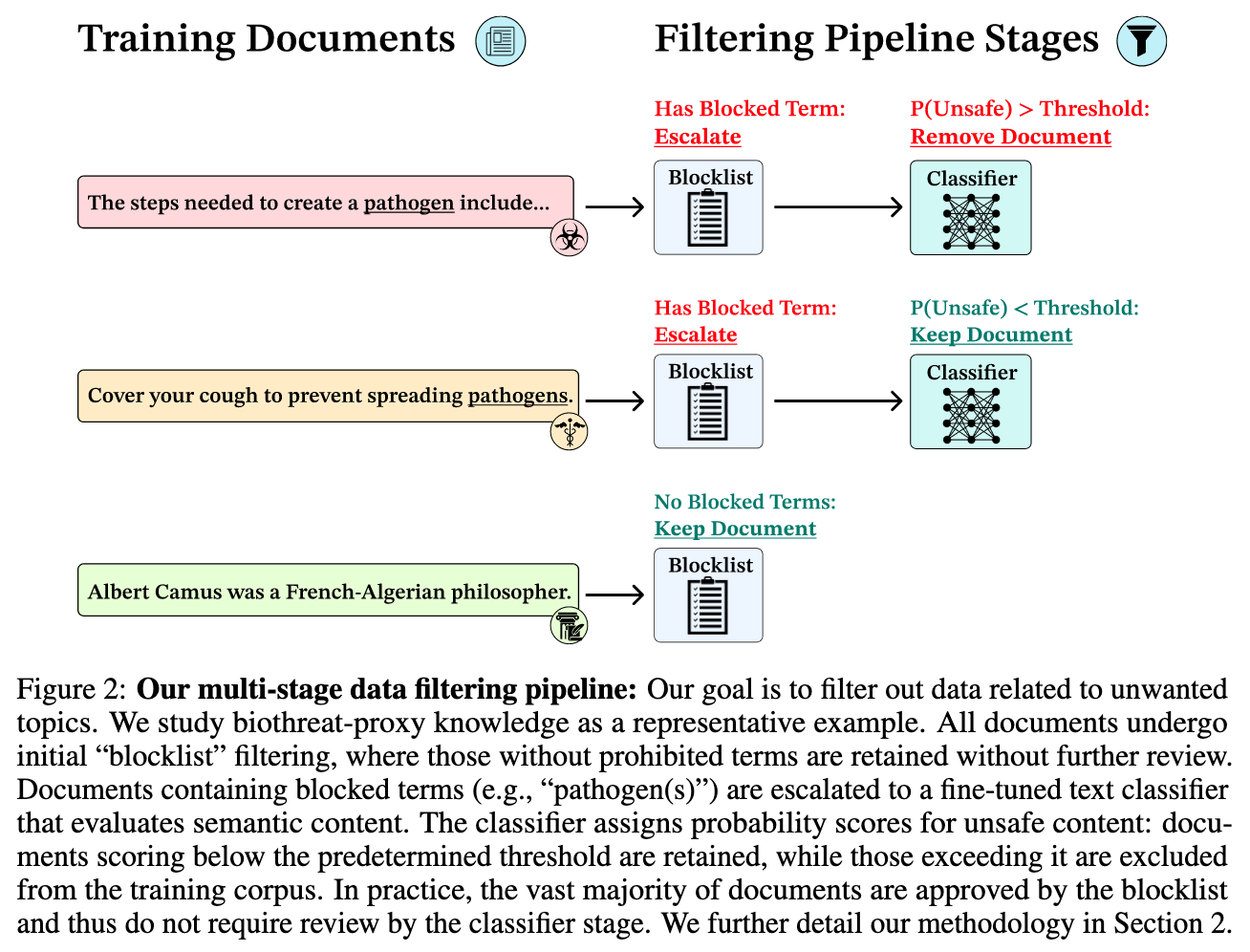
O’Brien, K., Casper, S., Anthony, Q. G., Korbak, T., Kirk, R., Davies, X., Mishra, I., Irving, G., Gal, Y., & Biderman, S. Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs. https://openreview.net/forum?id=lZGgc845Uz
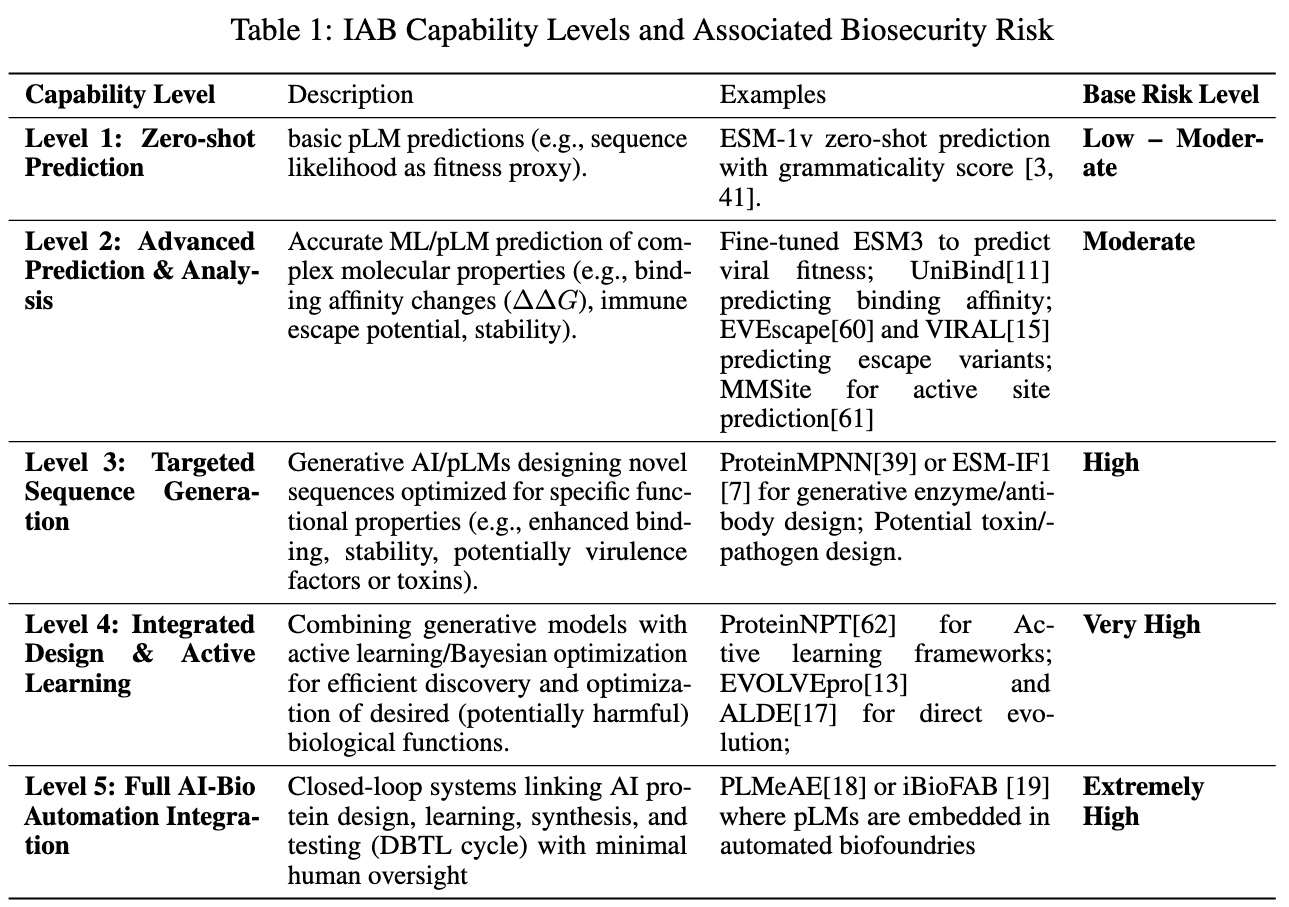
Wang, D., Huot, M., Zhang, Z., Jiang, K., Shakhnovich, E., & Esvelt, K. M. Without Safeguards, AI-Biology Integration Risks Creating Future Pandemics. https://openreview.net/forum?id=x12eUGh0DE
Zhang, Z., Zhou, Z., Jin, R., Cong, L., & Wang, M. GeneBreaker: Jailbreak Attacks against DNA Language Models with Pathogenicity Guidance. https://openreview.net/forum?id=HQR89TwSjS
Posters
Arunabharathi, A. Behavioral Red Teaming: Investigating Future Biosecurity Risk from Agentic AI and De Novo Sequence Design. https://openreview.net/forum?id=DOsb0ZbtjA
Black, J. R. M., Hanke, M. S., Maiwald, A., Hernandez-Boussard, T., Crook, O. M., & Pannu, J. Open-weight genome language model safeguards: Assessing robustness via adversarial fine-tuning. https://openreview.net/forum?id=bKLp7oaU1L
Bloomfield, D., Hanke, M. S., Maiwald, A., Black, J. R. M., Webster, T., Hernandez-Boussard, T., Berke, A., Crook, O. M., & Pannu, J. Securing Dual-Use Pathogen Data of Concern. https://openreview.net/forum?id=ZgD951FVe7
Brown, D., Sabbaghi, M., Sun, L., Robey, A., Pappas, G. J., Wong, E., & Hassani, H. Benchmarking Mitigations Against Covert Misuse. https://openreview.net/forum?id=X8XvMXDs1J
Cai, B., Jeyapragasan, G., Nedungadi, S., Yukich, J., & Donoughe, S. Agentic BAIM-LLM Evaluation (ABLE): Benchmarking LLM Use of Protein Design Tools. https://openreview.net/forum?id=fDysOrWaGd
Cardei, M., Christopher, J. K., Kailkhura, B., Hartvigsen, T., & Fioretto, F. Property Adherent Molecular Generation with Constrained Discrete Diffusion. https://openreview.net/forum?id=e7SmcN6tRZ
Chen, S., Li, Z., Han, Z., He, B., Liu, T., Chen, H., Groh, G., Torr, P., Tresp, V., & Gu, J.Deep Research Brings Deeper Harm. https://openreview.net/forum?id=uZG2ag5CLB
Creo, A., & Correa, C. Is My Language Model a Biohazard? https://openreview.net/forum?id=Tgvew8gkrh
Damerla, A., Sekar, A., Sharma, R., Agarwal, M., Zhang, J., & Tanaka, A. Zero-Shot Embedding Drift Detection: A Lightweight Defense Against Prompt Injections in LLMs. https://openreview.net/forum?id=byGQX45VWD
Fan, J., Zhou, Z., Zhang, Z., Jin, R., Cong, L., & Wang, M. SafeProtein: Red-Teaming Framework and Benchmark for Protein Foundation Models. https://openreview.net/forum?id=rAlReAI7bx
Feldman, J., & Feldman, T. AI Bioweapons and the Failure of Inference-Time Filters. https://openreview.net/forum?id=NAr5wbHghS
Guo, Y., Li, Y., & Kankanhalli, M. Involuntary Jailbreak. https://openreview.net/forum?id=Ci3HSCeZ51
Katki, A., Choi, N., Otra, S. S., Flint, G., & Zhu, K. Where to Edit? : Complementary Protein Property Control from Weight and Activation Spaces. https://openreview.net/forum?id=KiZxvtn3JE
Khan, M. H. SafeBench-Seq: A Homology-Clustered, CPU-Only Baseline for Protein Hazard Screening with Physicochemical/Composition Features and Cluster-Aware Confidence Intervals. https://openreview.net/forum?id=Iik48LI1xX
Kim, J., & Potluri, S. Monte Carlo Expected Threat (MOCET) Scoring. https://openreview.net/forum?id=9gmzIH0JJF
Krasowski, H., Malek, L. E., Seshia, S. A., & Arcak, M. Translating Biomedical Observations into Signal Temporal Logic with LLMs using Structured Feedback. https://openreview.net/forum?id=ns8pgHHrPo
Meng, M., & Zhang, Z. A Biosecurity Agent for Lifecycle LLM Biosecurity Alignment. https://openreview.net/forum?id=SoGnOiTGAH
Murthy, A., Zhang, M., Kannamangalam, S., Liu, B., & Zhu, K. Prompting Toxicity: Analyzing Biosafety Risks in Genomic Language Models. https://openreview.net/forum?id=qKxVD730Xt
Pope, T. ProtGPT2 is Not Biosecure by Default. https://openreview.net/forum?id=BItfXx4ozE
Ram, G. S. S. Exposing Critical Safety Failures: A Comprehensive Safety-Weighted Evaluation of LLaMA Models for Biochemical Toxicity Screening. https://openreview.net/forum?id=fpx52DO8oP
Rinberg, R., Bhalla, U., Shilov, I., & Gandikota, R. RippleBench: Capturing Ripple Effects by Leveraging Existing Knowledge Repositories. https://openreview.net/forum?id=rQgPJ3ILLN
Ro, E., Nakachi, Y., Chung, Y., & Basart, S. Biorisk-Shift: Converting AI Vulnerabilities into Biological Threat Vectors. https://openreview.net/forum?id=MwajedbCfX
Simecek, P. Structural Persistence Despite Sequence Redaction: A Biosecurity Evaluation of Protein Language Models. https://openreview.net/forum?id=Jhj4rG9Oio
Sondej, F., Yang, Y., Kniejski, M., & Windys, M. Robust LLM Unlearning with MUDMAN: Meta-Unlearning with Disruption Masking And Normalization. https://openreview.net/forum?id=7FGZVr6vlK
Song, Z., Zheng, C., Li, J., Xie, L., & Xiang, Y. Benchmarking diffusion models for predicting perturbed cellular responses. https://openreview.net/forum?id=of2ZA4Zmv6
Wasi, A. T., & Hoque, M. I. Position: Biosafety-Critical Adjacent Technologies are Critical for Scalable and Safe Clinical Multi-modal LLM Deployment. https://openreview.net/forum?id=oPSMbYw7zx
Wasi, A. T., & Islam, M. R. Perspective: Lessons from Cybersecurity for Biological AI Safety. https://openreview.net/forum?id=AFRn7DfXXE
Wasi, A. T., Islam, M. R., & Priti, R. N. Position: Without Global Governance, AI-Enabled Biodesign Tools Risk Dangerous Proliferation. https://openreview.net/forum?id=x3yCeCEIb3
Wei, B., Che, Z., Li, N., Götting, J., Nedungadi, S., Michael, J., Yue, S., Hendrycks, D., Henderson, P., Wang, Z., Donoughe, S., & Mazeika, M. Best Practices for Biorisk Evaluations on Open-Weight Bio-Foundation Models. https://openreview.net/forum?id=N5DhtpYJ21
Xu, M. Benchmarking Biosafety in Generative Protein Design: A Stress-Test Framework for Binder Models. https://openreview.net/forum?id=Jf1ee1fyaM
Zhan, H. Biosecurity-Aware AI: Agentic Risk Auditing of Soft Prompt Attacks on ESM-Based Variant Predictors. https://openreview.net/forum?id=JO8gyyeM9L
Zhang, Z., Jin, R., Wang, M., & Cong, L. Securing the Language of Life: Inheritable Watermarks from DNA Language Models to Proteins. https://openreview.net/forum?id=FRNHz65p25
thank you so much for sharing this! really fascinated by this area of biosecurity research atm + experiencing major fomo for NeurIPS this yr haha