
Five Things (May 15, 2026): AI is why we can't have nice things
GitHub problems, vibe coding regrets, Elsevier sues Meta, fabricated citations, the arXiv banhammer for AI-generated content
AI-heavy week, but the throughline is what happens when the platforms and infrastructure under our work start to rot, from GitHub to preprint servers to peer-reviewed literature.
The GitHub ship is sinking, the lifeboats leak
Vibe-coded into a corner
The Lancet sues the AI that cites The Lancet
Hallucinated citations, now with a denominator
arXiv takes the banhammer out for AI-written work
1. The GitHub ship is sinking, the lifeboats leak
David Bushell wrote a vivid eulogy for GitHub (“GitHub used to be cool and now it’s a lame slop graveyard”), and a few days later GitLab’s new CEO Bill Staples published “GitLab Act 2”, which to me sounds like a flailing pivot toward agentic everything.
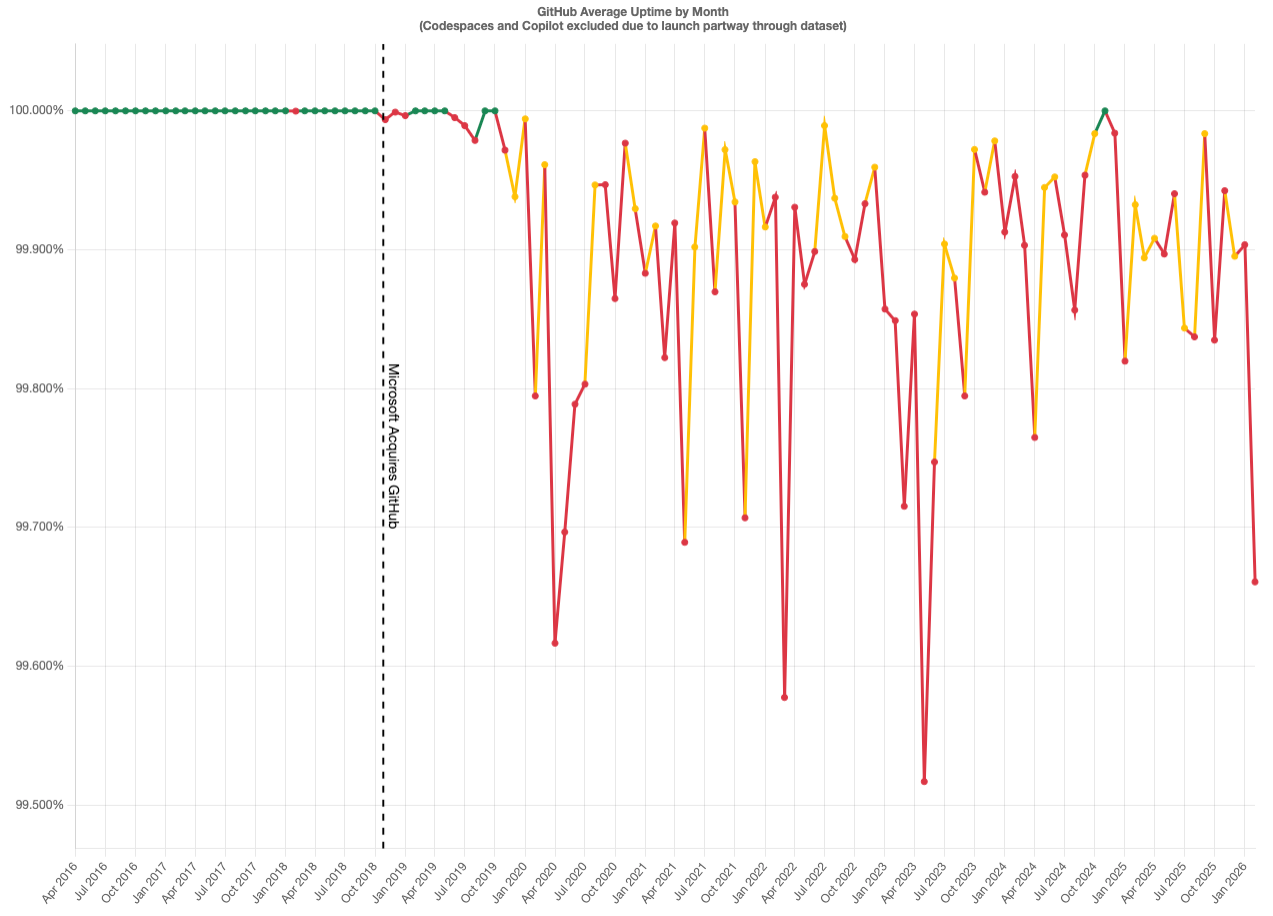
Bushell’s case against GitHub is part vibes but contains an uptime chart that does look bad after the Microsoft acquisition.
When I posted this chart on Bluesky earlier this week, I had a few folks pointing to the deluge of AI coding agents and automated pull requests as the reason. But if you look closely at the chart, this service degradation long predated AI coding agents and ChatGPT itself.
But: Git is not GitHub. He recommends Codeberg (running Forgejo) as the safe alternative, with self-hosted Forgejo as the power-user option. He also recommended GitLab, then added an edit:
oh dear, they’ve contracted the rot
The Staples letter is what he means. GitLab is reorganizing into roughly 60 smaller R&D teams, flattening management, exiting up to 30% of its country footprint, and (oh my): “rewiring internal processes with AI agents, automating the reviews, approvals, and handoffs to speed us up.” The strategic thesis is that “software will be built by machines, directed by people.”
The blog post calls git “designed for human-rate commits” and pitches a “generational rebuild of the underlying infrastructure to handle agent-rate work as the default.”
I’m not an agent power user, and maybe I’ll retract my thoughts on this in a few months. But, if your agents are opening so many merge requests that git itself is the bottleneck, the answer is probably fewer agents.
It’ll be interesting to see if this translates into actual migrations. Pretty much all of computational biology / bioinformatics lives on GitHub: software packages, snakemake/nf-core workflows, Bioconductor packages, lab repos, course materials. Don’t forget about other infrastructure as well: GitHub Pages (e.g. pkgdown pages for R packages), CI w/ GitHub Actions, GitHub container registry, etc. Moving the social graph (issues, PRs, stars, discoverability) is enormous work, and I don’t know if Codeberg could absorb the load. I can’t imagine what a realistic and practical exit plan would look like.
2. Vibe-coded into a corner
I’m not usually one to give air to the anti-AI hype. Most of what I read here is boring and irritating. However, Shubham’s “I’m going back to writing code by hand” is good. He spent ~30 weekends and >200 commits building k10s, a GPU-aware Kubernetes TUI, entirely through Claude. Then he sat down and read model.go for the first time. It was 1690 lines. He’s archiving it and starting over in Rust.
AI builds features, not architecture; every prompt landed cleanly, the cumulative effect was a god object. Vibe-coding “made everything feel cheap” so scope crept from a niche GPU tool to a generic k9s clone. My favorite line:
like “em-dash” is to ai writing, “god-object” is to ai coding
His proposed remedy is putting architectural invariants into CLAUDE.md or AGENTS.md so the model sees them on every invocation.
See also the HN thread. One comment stuck out: “Can’t you just ask AI to break up large files into smaller ones and also explain how the code works so you can understand it?” If the AI got you into the god-object hole, asking the AI to refactor its way out is probably not the move.
I was at a week-long innovation lab around AI and drug discovery this weekend. A thought in the back of my head all week was something I keep coming back to in my thinking in computational biology: the bottleneck in agentic science is evaluation, not generation. You can prompt your way to a working pipeline in a weekend. You can’t prompt your way to knowing it’s right.
3. The Lancet sues the AI that cites The Lancet
Elsevier has joined a class-action lawsuit against Meta alleging Meta reproduced copyrighted works to train Llama. As Nature notes, this is the first AI copyright suit from major publishing houses. Elsevier publishes Cell and The Lancet, so a fair chunk of the biomedical literature is now formally a plaintiff against a frontier lab.
The lawsuit alleges Meta used Common Crawl and also that Meta downloaded and torrented works from LibGen and Sci-Hub. Meta’s defense is the usual one: training is transformative use. US judges in two 2025 rulings reportedly distinguished between training (often transformative) and acquisition (the act of downloading copyrighted material), which is where torrenting from Sci-Hub is going to be a problem for Meta regardless of how fair use resolves.
Irony is dead.
Elsevier sells access to research funded by taxpayers and donated by authors who weren’t paid for the manuscript and often paid Elsevier APCs to make it open. Meta scraped some of that content, allegedly via Sci-Hub, which exists precisely because Elsevier’s access model is widely considered indefensible. Now Elsevier wants damages on behalf of authors who didn’t get paid the first time around either. The most coherent position is probably that Meta should have paid for licensed access and that Elsevier should not be the entity collecting the check, but that isn’t on offer.
If this case establishes that scraping paywalled academic content is infringement, the practical effect on open-science-trained models could be larger than the effect on Llama. Llama already exists. A future model that wants to train on biomedical literature now has a clearer legal target on its back.
4. Hallucinated citations, now with a denominator
A new Lancet correspondence by Topaz et al. audited 2.5 million biomedical papers for fabricated references, and the numbers are bad. The accompanying Comment by Bauchner and Rivara argues that any published paper with a fabricated reference should be retracted, which is a reasonable position that approximately no one will implement.
Topaz and colleagues pulled >100 million references from >2 million papers in PubMed Central’s Open Access subset between Jan 2023 and Feb 2026. They kept the 97 million (77%) with a PMID, verified those against PubMed, Crossref, OpenAlex, and Google Scholar, used Claude to filter reference errors (misformatted but real) from genuine fabrications, and validated precision at 91% with three independent reviewers. They found 4,046 fabricated references across 2,810 papers.
The fabrication rate increased more than 12 times, from approximately four per 10,000 papers in 2023, to 51.3 per 10,000 papers in the fourth quarter of 2025
The inflection point is mid-2024, which is when LLM-assisted papers would start clearing typical 100-200 day submission lags. One paper on ureteroileal anastomotic techniques had 18 of 30 verified references fabricated, each tailored to the surgical topic and attributed to real urologists. The authors also flag a paper-mill pattern: the same two-author pair appearing across 11 papers in a single surgical journal in 2025.
Read this along with #3 above. If Elsevier wins the case against Meta, the legal incentives push toward licensed-only training data. The Lancet audit suggests the academic literature itself is already meaningfully polluted by models trained on it. I think this will get worse before it gets better.
5. arXiv takes the banhammer out for AI-written work
Yesterday, Thomas G. Dietterich (arXiv moderator for cs.LG) announced that arXiv will implement 1-year ban for papers containing incontrovertible evidence of unchecked LLM-generated errors, such as hallucinated references or results. Here’s the full text of the thread:
Attention arXiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated.
If generative AI tools generate inappropriate language, plagiarized content, biased content, errors, mistakes, incorrect references, or misleading content, and that output is included in scientific works, it is the responsibility of the author(s).
We have recently clarified our penalties for this. If a submission contains incontrovertible evidence that the authors did not check the results of LLM generation, this means we can’t trust anything in the paper.
The penalty is a 1-year ban from arXiv followed by the requirement that subsequent arXiv submissions must first be accepted at a reputable peer-reviewed venue.
Examples of incontrovertible evidence: hallucinated references, meta-comments from the LLM (”here is a 200 word summary; would you like me to make any changes?”; “the data in this table is illustrative, fill it in with the real numbers from your experiments”).
I’m about as split on this one as the comments on the OP are. On one hand, GOOD. Hallucinated citations and unchecked AI-authored content is polluting the literature everywhere. I think this borderlines on scientific misconduct, and it destroys trust in the entire scientific enterprise.
Oh the other hand there are lots of problems with detection and enforcement. AI detection software is a cat and mouse game that doesn’t work reliably. And on the enforcement side — what happens when you’re a co-author on a paper with a hallucinated citation? Say I tell my grad student to work on the methods section and they get an undergrad to write a small section that they worked on, and said undergrad carelessly inserts a fabricated citation. If this paper makes its way onto arXiv, does that infraction go all the way up the chain with the banhammer coming down on all co-authors? Have you ever submitted a paper written with a bunch of co-authors and meticulously looked up every reference or checked that every parameter setting in the detailed methods section is actually a valid parameter for whatever tool was being used? I have.
I think a middle ground solution with a big red banner or warning flag on the abstract page or search results noting that the paper likely contains unverified AI-generated content.
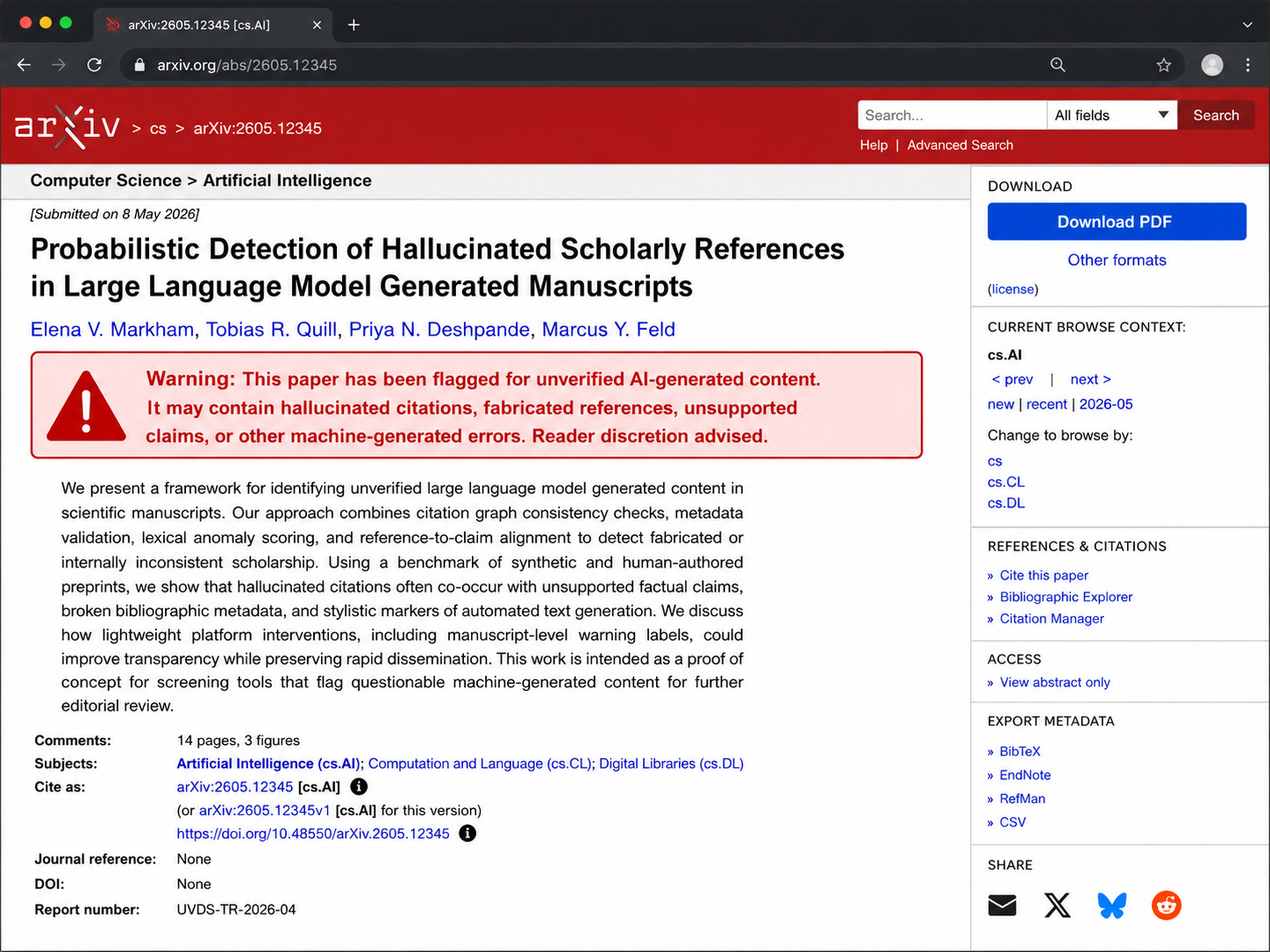
Again, the detection piece is difficult, and authors should be given a chance to respond before getting the scarlet letter. I think the 1-year ban is severe, and if applied to all co-authors, could be extremely damaging to one’s career just because a middle author responsible for page 98 of a large supplemental info section was careless and wasn’t carefully scrutinized. I also worry that such a ban could be inconsistently applied since there’s a lot of subjectivity and guesswork involved with this endeavor.
Stephen, I am so totally with you on the hypocrisy of Elsevier...but I'm still kinda glad they're suing Meta.
I'm a bit surprised your concern on arXiv banning is about the impact of a middle author including LLM content without appropriate checking by the first and last authors. I agree the punishment is too harsh, but they should be checking. Much more concerning to me is the *career* of the middle author, who contributed but isn't in charge of the final read-through. Hopefully not all co-authors are included in the arXiv ban.
Regarding your scarlet strip: I think that's a fine idea. But arXiv could also provide the tool for checking for LLM issues, and tell people their submission is non-compliant before posting.