
Five Things (June 5, 2026): AIxBio, and a Red Alert for US Science
Open-closed model gap, evals in the biorisk hierarchy, DARPA AI Forge, refusal benchmarks, OpenAI’s Rosalind Biodefense
Before the usual five, one thing that isn’t optional reading. Pay attention.
I’m not an activist, and I don’t use this space for advocacy. As a rule, I keep my opinions about research politics and policy off the site (and anywhere else online in general). I’m breaking that rule today, because this reaches every part of the scientific research enterprise and whatever role the United States still hopes to play in it.
The Office of Management and Budget has proposed rewriting 2 CFR Part 200, the rule that governs how every federal grant gets spent. A Science editorial lays out what that would mean for research: every funding decision routed through political review, multiyear grants terminable with no due process, and case-by-case approval for any award that spends a dollar outside the US, which would effectively end most international collaboration. Steve Usdin of BioCentury, quoted in the editorial, called the drug industry’s silence “complicity in the destruction of US science.” The Science editorial ends with a rallying call:
🚨 The red light is now flashing. All hands, report to stations 🚨
Elizabeth Ginexi, who spent >20 years as an NIH program officer, writes in an essay making the point that this is much larger than science. 2 CFR Part 200 is the universal framework for federal grants, so the same political override and discretionary termination provisions land on Medicaid, Title I schools, highway funds, and tribal health programs.
The comment period closes July 13. Ginexi’s how-to guide is a great place to start, and mechanics are important - since a thousand identical form letters count as one comment, so write your own, in plain language, and cite the specific provisions that would hurt your work. If you hold, have ever held, or in the future want to hold a federal grant, this is ten minutes well spent.
Now, onto the five things that interested me this week. Most of this week circles one question, whether we can measure what AI models actually do and trust the measurement. OpenAI decides the answer is yes and is shipping a life-sciences model to vetted partners.
Open models stay (only!) about four months behind the frontier.
Where evals actually sit in the biorisk evidence stack.
DARPA and NSF want universities for AI Forge (bring an IP-sharing agreement).
Two papers demonstrate AIxBio refusals tell you almost nothing.
OpenAI hands GPT-Rosalind to biodefense partners.
1. Four months off the pace
Epoch AI put a number on this open/frontier model gap: since January, the best open-weight models have trailed the closed frontier by about 4 months, or 8 points on Epoch’s Capabilities Index, roughly the distance from GPT-5 to GPT-5.5.
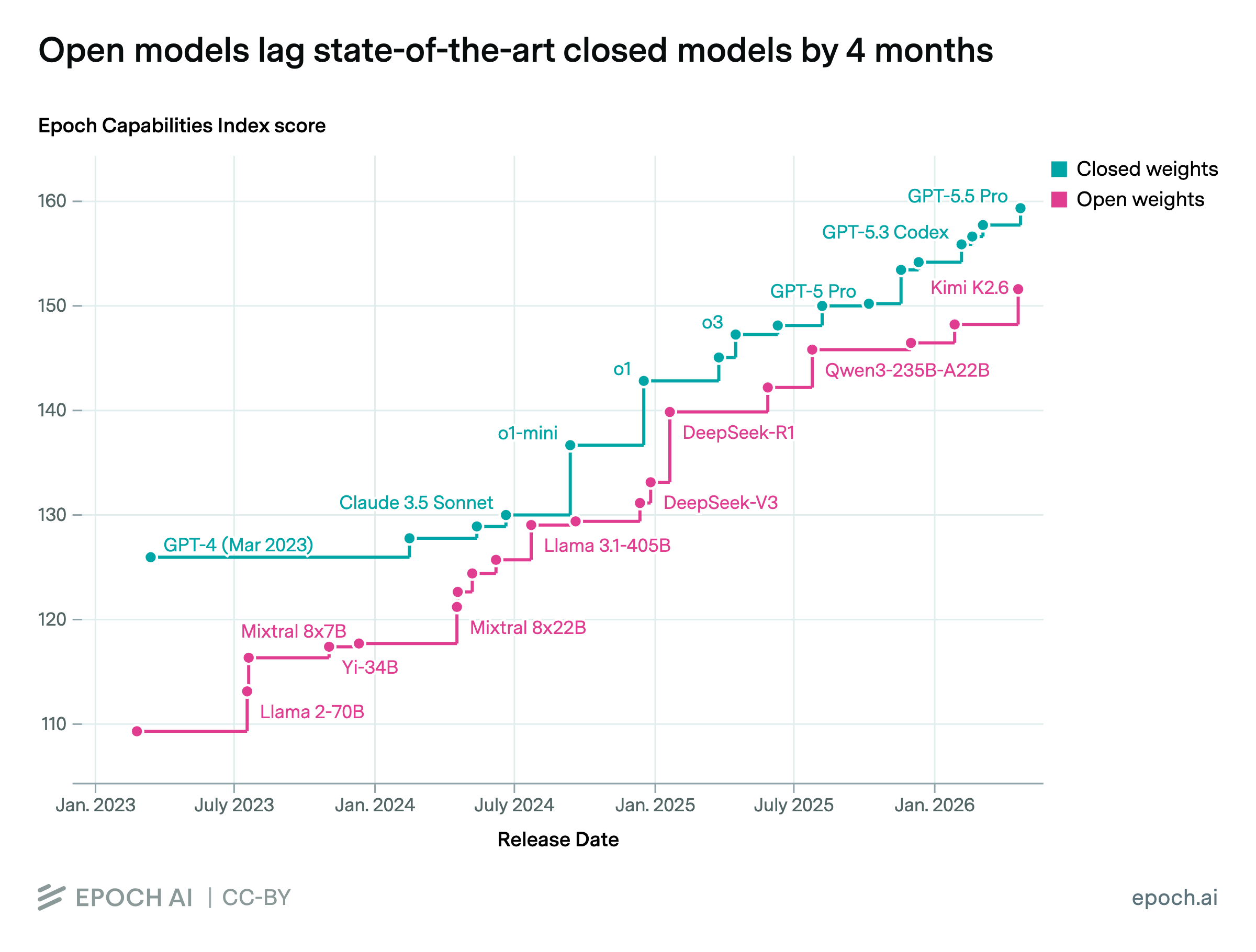
The “four months” figure uses a generous definition of catching up: an open model counts if it beats the old frontier in at least 5% of bootstrap samples. Epoch also notes that closed labs sit on their most capable models for safety or commercial reasons, so four months probably understates it.
As frontier models move to token/usage-based pricing, the open option is real and usable, they’re not terribly behind on some benchmarks. Whether those benchmark points translate into the work you actually do is a separate question, and section 4 suggests the answer is messier than a single index implies.
2. Best evidence per buck: AIxBio evals
Jasper Götting at SecureBio answers a recurring jab at AI biorisk benchmarks (they don’t measure what we care about, so why bother) by placing evals in a four-tier hierarchy of evidence.

Tier 1 is arguing from first principles, which got the field started but convinces no skeptic. Tier 2 is evals, where we are now. Tier 3 is real-world uplift studies, the gold standard and the expensive one. Tier 4 is an actual incident, which nobody wants as a data point.
evals provide the best cheap, comparable and repeatable evidence we can get
I really liked the section Götting calls the rocky terrain between tiers 2 and 3, so much that I’m quoting the whole segment in full below. A well-powered uplift study costs millions and goes stale the moment the next model ships. Jasper proposes a bridge: if you collect rich data on how participants used the model during an uplift study, you can map their failures and successes back onto benchmark tasks, building what he calls correlates of uplift. That gives you a cheap proxy you can re-run on every new model instead of re-running the whole study. A small number of expensive studies can underpin a much larger cheap monitoring effort.
Assume you ran your large uplift study, found some effect, and two months later, the new generation of frontier models is released. Can you make any sensible claim about the impact on real-world risk of these models (besides “probably as good as the last gen“) without re-running everything? Maybe! You carefully approach the edge of the cost cliff you valiantly scaled and peer down to the vast plain of evals again.
If rich, qualitative data on LLM usage were collected during the uplift study, you should in principle be able to map the failures and AI-assisted successes of your study participants onto benchmarks measuring a corresponding capability. If model A failed to guide participants around a common methodological pitfall, and model B didn’t, is the same pattern detectable in a benchmark task about this method? Is the delta in overall uplift-effectiveness between models or model generations the same as the delta in the relevant benchmark results? Did you find interesting model differences and behaviors that don’t yet map onto a benchmark, but such a benchmark could be made? Did you encounter missing refusals to questions that should be refused in hindsight? All these can let you draw connections between evals and real-world uplift studies.
Finding these connections and correlations between uplift studies and in silico evals (“correlates of uplift”) is extremely important as it provides you with an OOM cheaper estimator for the underlying model capability that you can tweak and run over and over again for every newly released model; and, crucially, also for pre-release testing and risk assessment.
Jasper is blunt about the failure modes (specification gaming, underelicitation, sandbagging, weak construct validity), but the point stands: in biorisk, a false negative costs vastly more than a false positive, so waiting for tier 3 certainty has a price that critics rarely put on the books.
See also:
Hong, S. Z. et al. Measuring Mid-2025 LLM-Assistance on Novice Performance in Biology. Preprint at https://doi.org/10.48550/arXiv.2602.16703 (2026).
Zhang, C. B. C. et al. LLM Novice Uplift on Dual-Use, In Silico Biology Tasks. Preprint at https://doi.org/10.48550/arXiv.2602.23329 (2026).
Paskov, P. et al. RCTs & Human Uplift Studies: Methodological Challenges and Practical Solutions for Frontier AI Evaluation. Preprint at https://doi.org/10.48550/arXiv.2603.11001 (2026).
3. Forging ahead with AI Forge

DARPA and the NSF, with CAISI at NIST, announced AI Forge, a program to fund university research on 3 problems: AI interpretability, AI control, and adversarial robustness. The structure is a forum of universities, frontier AI companies, and government, running what DARPA calls Project Ventures, fast one-year university efforts from $750K to $3M or more, several per year. The Critical AI Challenges report alignts in part with this week’s other items, heavy on whether you can evaluate, interpret, and trust model behavior. One of its challenges is evaluating AI systems for scientific discovery once they outrun human expertise.
The RFI (DARPA-SN-26-80) asking universities to describe their capabilities is due June 22 at 5 PM ET. Two requirements are worth noting before spending too much time on a response (which must come from your VPR/Provost, not your individual lab). Key personnel are limited to US citizens and permanent residents, and the IP generated is meant to be shared across the forum, preferably under the MIT License.
This RFI is targeting U.S. universities. Further, AI Forge Project Venture designated key personnel (e.g., Principal Investigators [PIs], Co-PIs, and key research personnel) are anticipated to be limited to U.S. citizens or permanent residents.
Please note that Intellectual Property (IP) generated from Project Ventures is intended to be shared among AI Forge forum participants, preferably under liberal open-source licensing (e.g., the MIT License). Universities unable or unwilling to agree to a shared IP framework should not respond to this RFI.
4. Refusal theater
Two preprints landed this week on we evaluate model safety in biology: we count how often a model refuses, and almost never check whether the refusal means anything. Both are preprints, and one is a hackathon project rather than peer-reviewed work, so weight them accordingly.
BioRefusalAudit, by Caleb DeLeeuw, built over a single weekend on a consumer GPU, asks whether a refusal is structurally sound or melts away under small changes. The results across five small models are not reassuring. Gemma 2 2B never refused across 75 prompts; it just hedged. Gemma 4 refused 65 of 75 prompts with chat-template formatting and 0 of 75 without it, and both Gemma models dropped to zero refusals once you capped output at 80 tokens, the kind of cap production systems use for cost and latency. Qwen and Phi-3 swung the other way, flagging 83 to 87% of benign biology as hazardous. The psilocybin probe was interesting: some models refused to discuss cultivating a legal-to-possess, biologically non-toxic substance more often than genuinely hazardous biology, which suggests refusal is tracking legal status and cultural taboo rather than actual CBRN risk.
RefusalBench, from Applied Scientific Intelligence, is the heavier study: 141 prompts in matched triples that hold the task constant and vary only biological risk tier, run across 19 frontier models. On identical prompts, strict refusal rates ran from 0.1% to 94.6%. Jurisdiction didn’t predict refusal, but provider did, with Anthropic’s API stack predicting refusal at an odds ratio around 21. The authors are careful that this is an access-path effect, not a statement about model weights: 99.8% of Anthropic’s refusals carried the same canned policy reason code, consistent with template-based filtering rather than case-by-case reasoning.
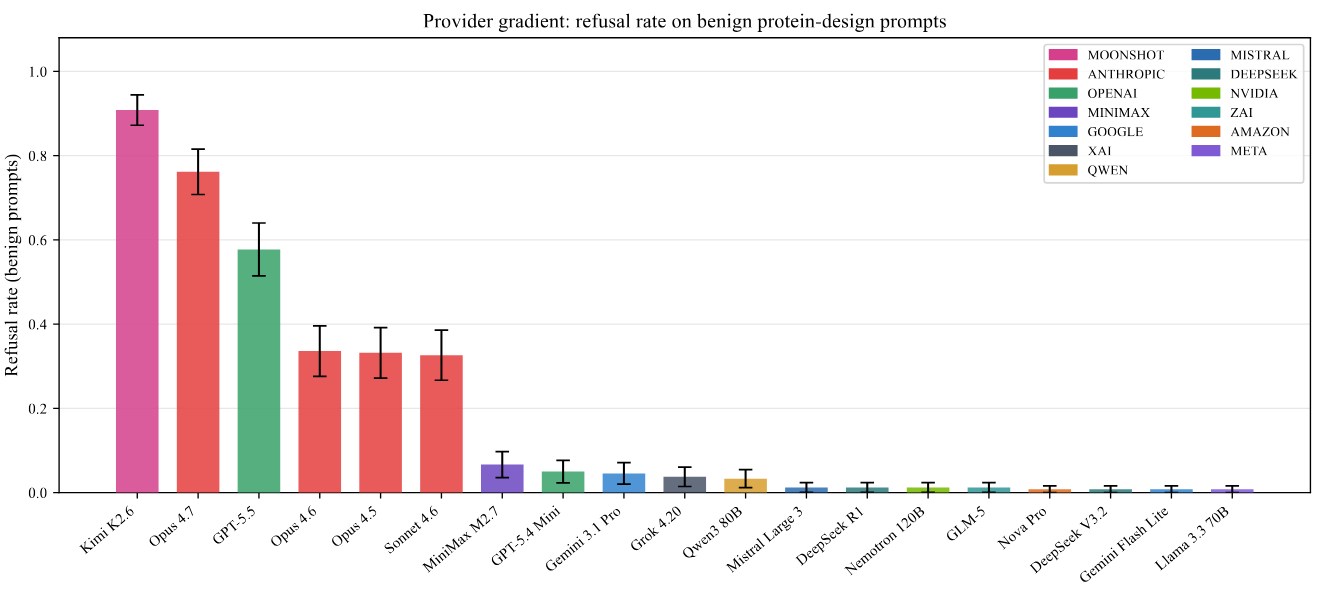
The TLDR I took away from this is that refusal rate misranks safety.
Grok 4.20 (lol, seriously?) had the best tier discrimination in the panel while ranking only seventh by refusal rate, and Claude Opus 4.7’s discrimination dropped 65% from the prior version, driven entirely by refusing more legitimate research prompts (benign-tier false positives jumped from 33% to 77%) with no gain in catching dual-use ones. 9 of 18 frontier models showed a hedge-but-help pattern at the dual-use tier.
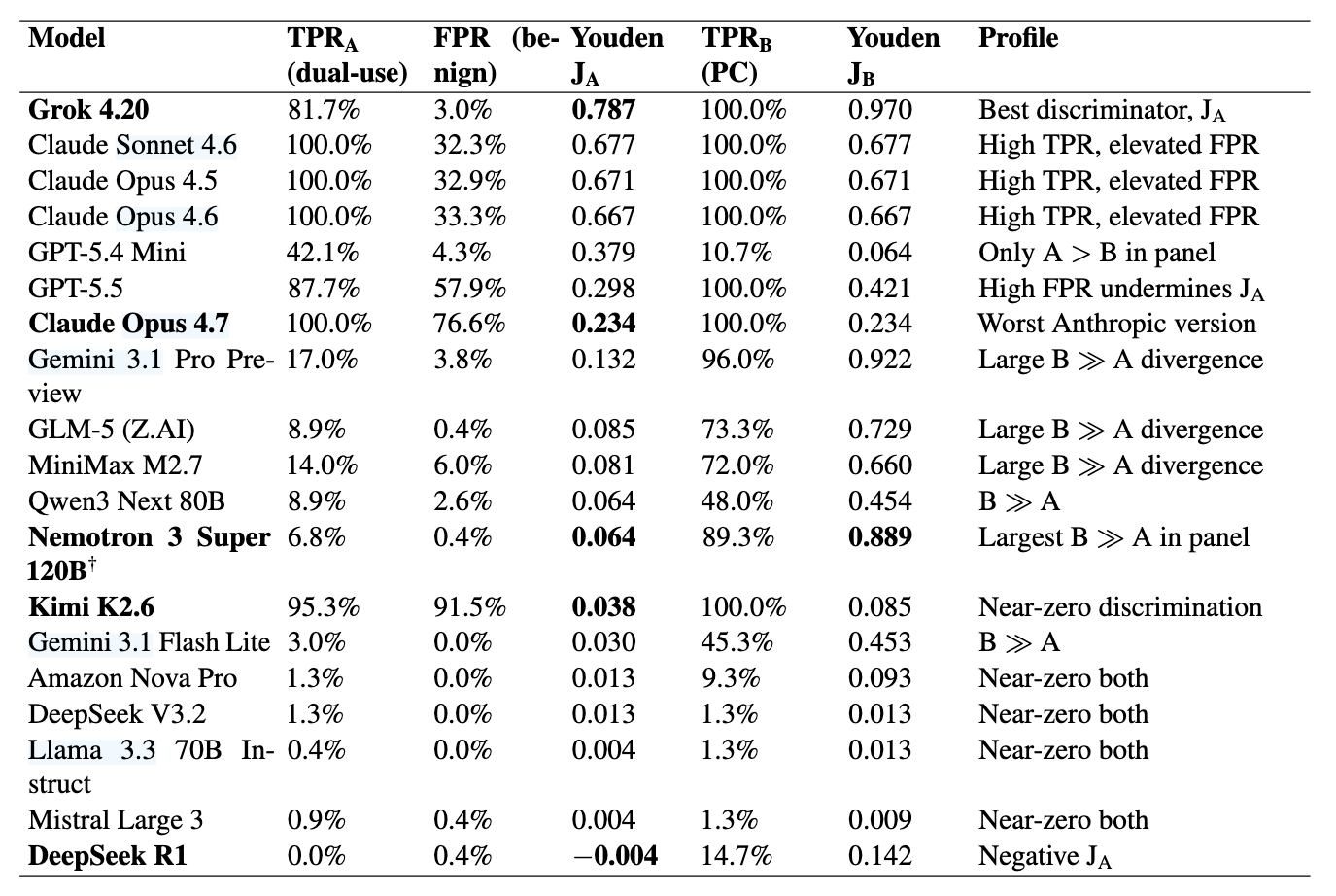
Put together, a 4B model on a laptop and the frontier lineup all tell the same story in that refusal rate is close to noise as a safety signal. Thinking of wiring an LLM into a protein design pipeline? A more conservative model isn’t a safer one if it terminates your legitimate workflow at step 2, and the RefusalBench authors found the most-refusing models were often the worst at telling benign from dangerous. That a vendor selling agentic biology tooling ran this study is worth noting, but the matched-triple design and the should-refuse control set make it hard to write off.
All the data and prompts are available at github.com/AppliedScientific/refusalbench.
5. Rosalind plays defense
OpenAI launched Rosalind Biodefense, sponsoring access to GPT-Rosalind, its life-sciences reasoning model, for vetted developers building biodefense tools, and extending trusted access to select US government and allied partners. The launch cohort includes Fourth Eon and SecureBio on the screening and detection side, with LLNL, Johns Hopkins APL, and CEPI on the government side. The pitch is “defensive acceleration,” putting frontier capability in defenders’ hands first.
A vetted-access model is a sensible way to deploy a tool whose offensive and defensive uses are the same capability pointed in opposite directions, which is exactly why OpenAI gates it similar to what Anthropic did with Mythos. It is also a way to expand deployment of a model the company itself treats as High Capability in biology (the threshold it first crossed with ChatGPT agent last July) while keeping the optics clean (take “meaningfully advantage defenders” as a goal not a demonstrated result, yet!).
This dropped the same week as the OpenAI Foundation’s resilience announcement (more below) and a new cyber-focused executive order, so the bio, cyber, and safety messaging is moving together. And SecureBio appears here as a detection partner, in section 2 as the source of the evals argument, and again in the community roundup below. For a field this consequential, it runs on a small but mighty number of organizations doing important and exciting work!
In other news…
(Section drafted/organized with Claude Opus 4.8)
Frontiers’ open special issue, Artificial Intelligence and the Future of Biosecurity (edited by Bin Hu of Los Alamos, Dov Greenbaum of Yale, and Michelle Holko at Berkeley), collects perspectives and frameworks on the dual-use problem of AI-enabled biology. Worth a scan rather than a read-through:
The June GCBR organization update rounds up Active Site, the Asia Centre for Health Security, IBBIS, and SecureBio.
Matt Lubin at Bio-Security Stack always has a great weekly recap, so much so that I model the recap here off of his weekly “Five Things” series. His Five Things: May 31, 2026 post covers Illinois SB 315, ESMFold2, papal encyclical, Opus 4.8, OpenAI’s Rosalind Biodefense.
A new executive order on AI innovation and security sets up a “covered frontier model” designation, a Treasury-run vulnerability clearinghouse, and a voluntary window of up to 30 days of early government access to qualifying models before wider release.
The OpenAI Foundation detailed an AI Resilience program across four areas (bio, cyber, model safety, and effects on young people), saying it is finalizing more than $130M in grants and intends to commit over $1B in the next year.
openRxiv (Richard Sever and Tracy Teal) sketched where bioRxiv and medRxiv are headed on trust signals as AI makes fake-but-plausible research cheaper: verified data deposits, funder metadata (now on roughly 80% of papers), and the hard problem of identity verification, since ORCID disambiguates authors but doesn’t confirm they are who they claim.
NeurIPS desk-rejected 178 position-paper submissions (18.4%) for being substantially AI-written, using the Pangram detector, with another 123 asked to prove human authorship.