
Do the carbon math. Make ethically cautious but socially adventurous choices. Try something.
Quoting Charlie Loyd's remarks from the Potato pansharpening environmental impact analysis
Potato (github.com/celoyd/potato) is a pansharpening model and Python package developed by Charlie Loyd. The README has a nice explainer on what pansharpening is. Briefly, a high-res satellite image has two parts: a grayscale image at full resolution, and a full color image at lower resolution. Pansharpening is the process of merging the sharp grayscale image with the full-color blurry image to get a sharp + full-color image. Potato is a tool to do this.

I’ve never done anything with satellite imagery in my work, and I doubtfully ever will. What I found interesting about this repo is the Environmental Effects section at the end of the README, which quantifies the carbon emissions required for training and usage.1
Do the carbon math. Make ethically cautious but socially adventurous choices. Try something.
The repo is licensed CC-BY-NC, so I’ve copied the entire environmental effects section below. See the current version at github.com/celoyd/potato.
I’ll assume, based on my GPU’s power rating and benchmarked generation rate, that Potato runs at 150 J/s and 12.5 megapixel/s, or 12 J/Mpel. (It uses 3.5 to 4× as much energy per work if run entirely on the CPU; only the GPU is considered here. Current-generation GPUs are roughly twice as efficient, and can also run at half precision, so may approach 3 J/Mpel.)
CAISO, the local grid authority, does not publish marginal GHG intensity, so I’m working from estimates like figure 2 in Mayes et al. 2024 (from 2021, when the grid emitted ~30% more). My GPU use is very sensitive to the temperature of my living space, which (given California’s cooling-heavy duck curve) shifts it to grid-friendly times: the GPU is nearly always idle at peak, and in winter, it’s substituting residential heating. My best point estimate of my marginal intensity is 160 g/kWh.
A CO₂e intensity of 160 g/kWh at 150 W = 6.7 mg/s = 24 g/hour = 575 g/day = 18 kg/month = 210 kg/year. This is the estimated CO₂e production of continuous Potato use on my hardware. From the processing rate, we also get a CO₂e/pixel estimate: 536 µg/Mpel = 536 grams per terapixel.
The training data has a mean ground sample distance of about 50 cm per pixel: a density of 4 Mpel/km². This gives us the CO₂e per area processed of 2.15 mg/km². We can now estimate, for example, the carbon emissions of pansharpening Earth’s whole land surface at that GSD with Potato: 320 kg (over a year and a half, if on my agèd GPU).
My estimate for Potato’s total training time is 5 GPU days. (When I first wrote this paragraph, it was more like 3.5, but my estimate has turned out about right, I think.) Training draws about the same power as inference, since both nearly saturate the GPU. So the GPU-originated emissions embodied in Potato’s trained weights are about 3 kg CO₂e.
Remarks
A few comparisons for context:
My personal carbon emissions rise, on average, 2% over whatever they would otherwise be while I’m using Potato.
At this level, Potato in continuous use emits about 2/3 as much CO₂ as I do by exhalation.
Our compact car emits on the order of 100 g CO₂e/km, similar to a widebody commercial flight (pax⁻¹). All my Potato work is thus similar to inducing a single 30 km car trip, or, spread over a year, 82 extra meters of driving per day, or, at urban arterial speeds, 5.2 seconds of extra driving per day. (Or 2 minutes of extra widebody flying per year.)
Potato’s total emissions to date are roughly equivalent to that embodied in 30 g (1 oz) of conventionally farmed steak, one large hand of bananas, or 150 g (6 oz) of chocolate. Or 10 kg (22 lb) of potatoes – a carbon-friendly food, and much more nutritious than most assume.
The dominant factor in Potato’s direct greenhouse forcing effects to date, as far as I can account for them, has been food and drink choices I have made while working on it.
The assumption that deep learning is necessarily wildly energy-hungry only serves to benefit the outliers who do it in wildly energy-hungry ways. I will give them no cover. Our moment deserves a sprawling, heterogeneous, complex ecosystem of individuals and small groups tinkering with these technologies, charting possibility spaces and developing bottom-up understandings, independent of any business goals, and with hobby-scale carbon emissions. I see only shadows and echos of that.
For example, from what I’ve heard, there is much to admire in what the RWKV people are doing: producing capable models with computing resources that large companies give away for free, making the creation of accessible tools an explicit ideal, and without externally determined goals. Perhaps if I looked closer I’d notice them doing things I disagree with – but all the more reason I should be able to name a dozen peer groups to RWKV, each with its own choices, ethos, and technical interests. I can’t. And I think that’s a serious problem.
We all live in a blighted landscape ML-wise: an ecosystem without a middle. We have kaiju-like companies that shake the ground with every step. We have millions of consumerified “AI” users, the economic equivalents of algal mats, almost all without any practical options other than choosing which models to pay for and how to prompt them. What we don’t have in plenty are, in the ecosystem metaphor, the ordinary iguanas, caribou, and wallabies; the salamanders, honeybees, and potatoes. These are the RWKV peers, the people making their own pansharpeners and birdsong decoders. They are rare and even more rarely organized.
The kaiju, battling each other off in the haze, project the impression that there is no point doing anything unless you’re big enough to level forests while you do it: that it would be irrational to even try to compete with them, because you can’t burn enough carbon to play their game. Credulous “AI skeptics” transcribe these roars and psionic blasts with concern, as if they are good-faith veridical statements that we should accept uncritically. After all, the kaiju are the experts! If even they say you have to spend a petajoule and act like a kaiju to do anything interesting, why should we doubt them? And so the algae-and-kaiju world maintains itself.
No. There are thousands of niches available in individual- to chat-server–scale ML work that uses data and energy conscientiously and tries to understand this odd technology on terms other than those chosen by the kaiju and accepted by their pseudo-critics. Come be an octopus, a mangrove, or an okapi.
I’m not telling you to make a state-of-the-art LLM on your home computer. I’m telling you that the world of ML is bigger, more interesting, and better than O(n²) chatbots with 10,000,000,000 parameters.
Do the carbon math. Make ethically cautious but socially adventurous choices. Try something.
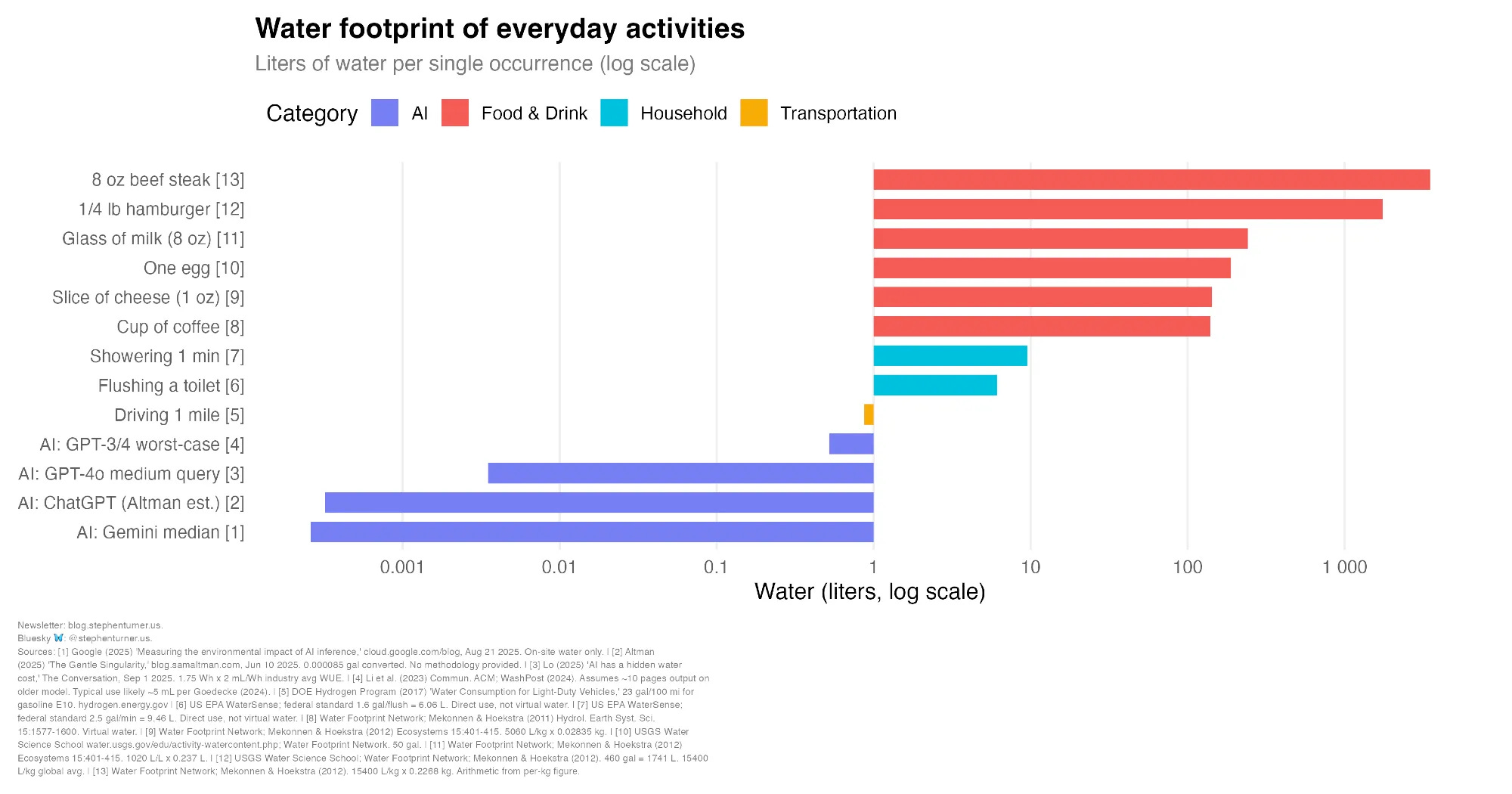
The statement in this repo is about carbon emissions, but I frequently hear misguided discussions around water usage. I’ve been vegetarian most of my life, vegan off and on. A fact I usually keep to myself. But please, go ahead and scold me about AI and water usage between bites of your burger.
Psionic blasts? From what...illithids? :-)