
AI-Assisted Customer Screening for DNA Synthesis Orders
A new preprint shows AI can handle legitimacy verification at a fraction of the cost.
Earlier this week I wrote about a paper by Jacob Beal (Raytheon BBN Technologies) and Tessa Alexanian (International Biosecurity and Biosafety Initiative for Science, IBBIS) on creating enforceable biosecurity standards for nucleic acid providers.

It’s a good paper, and I recommend reading it! I noted toward the end of the post that the customer screening side felt a bit undercooked. Tessa Alexanian, one of the paper’s coauthors, left a comment (thanks Tessa!) pointing me to additional work she and Sarah Carter had done on translating customer screening guidance into practical tools, and to a new preprint from Acelas et al. evaluating AI-assisted customer verification for synthetic nucleic acid screening.
Acelas, A., Palya, H., Flyangolts, K., Fady, P. E., & Nelson, C. (2026). Evaluating AI-Assisted Customer Verification for Synthetic Nucleic Acid Screening. bioRxiv 2026.02.27.708645; doi: https://doi.org/10.64898/2026.02.27.708645.
Here’s the problem the paper addresses: When someone orders a synthetic nucleic acid that matches a sequence of concern, the provider needs to verify that the customer is who they say they are and has a legitimate reason to order it. This legitimacy screening involves checking institutional affiliations, email domains, sanctions lists, and relevant publications or patents. It’s tedious, largely mechanical work, and the cost discourages adoption. Legitimacy screening runs roughly ten times more expensive per order than sequence screening alone.
Acelas et al. tested 5 LLMs (Claude Sonnet 4, Gemini 2.5 Pro, Grok 4, GLM 4.6, and MiniMax M2) on these verification tasks against a human baseline, using 41 customer profiles paired with simulated orders for sequences of concern. The best-performing model, Gemini 2.5 Pro equipped with bibliographic and sanctions APIs, achieved a 90% overall pass rate compared to about 80% for human screeners. Total cost per customer dropped from $14.04 for manual screening to $1.18 with AI assistance. For the information-gathering tasks alone (excluding human review of the final decision), the average was $0.23 per customer, roughly 50 times cheaper.
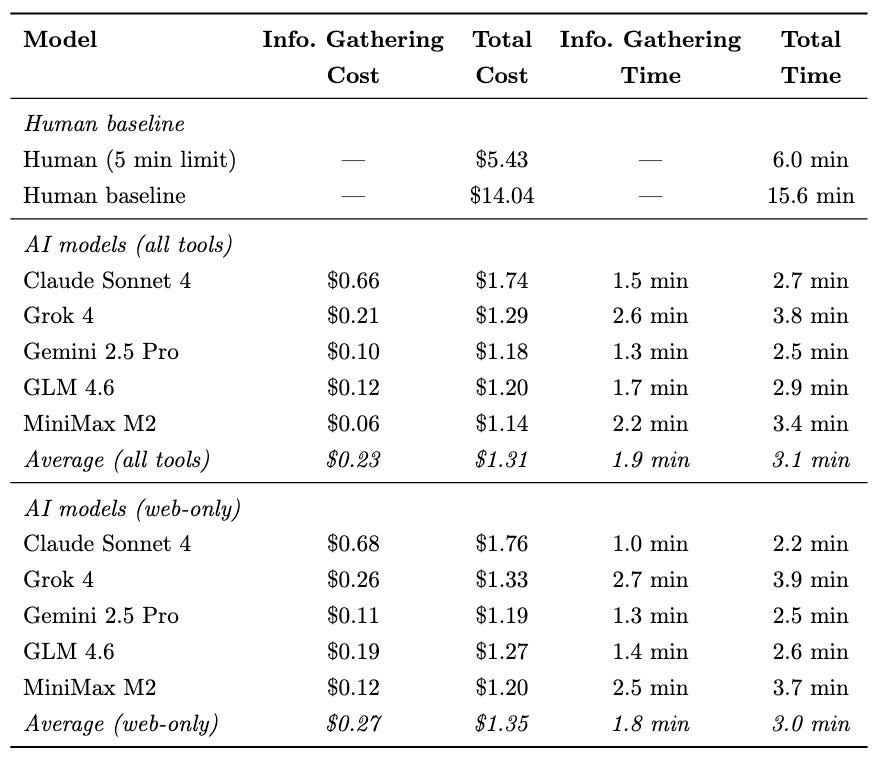
A couple things stood out. First, cost and performance were uncorrelated across models (Section 3.2 of the paper). The best model, Gemini 2.5 Pro, was also the second cheapest. Open-source models with lower per-token pricing lost their cost advantage through higher token consumption and more search queries. Second, giving models access to specialized tools (ORCID, Europe PMC, a sanctions list API) helped on most tasks but actually hurt on background work search, because models with API access performed fewer web searches and missed patents and news articles not indexed in academic databases (Section 3.1). Third, geographic variation in error rates. Chinese customers had notably higher missed-flag rates on email domain verification, largely because researchers there more often use personal rather than institutional email addresses (Section 3.3.1).
The authors are careful to note that the final ship-or-reject decision should stay with humans. AI handles the information gathering but a person decides what to do with it. This feels like the right framing, and as Tessa noted in her comment, the emergence of tools like Cliver (the screening API released alongside this paper), means providers increasingly don’t have to build this capability from scratch. That lowers the bar for adopting customer screening, which in turn makes it more reasonable to expect higher standards across the industry.